
-
本篇的几个实验都是增删改查的
-
实验五的二关,group by和order by的排序问题,实验5的10关,if插不进去,实验5的11关数据不对,12关做不了
数据库实验一
第1关:建立数据库
建立library数据库
并显示所有数据库CREATE DATABASE library;
show databases;第2关:建立读者数据表
①切换到图书(library)数据库;
②创建读者数据表(dz)数据表(指定表结构如下图所示);
③查看数据表的详细结构;
数据表结构如下: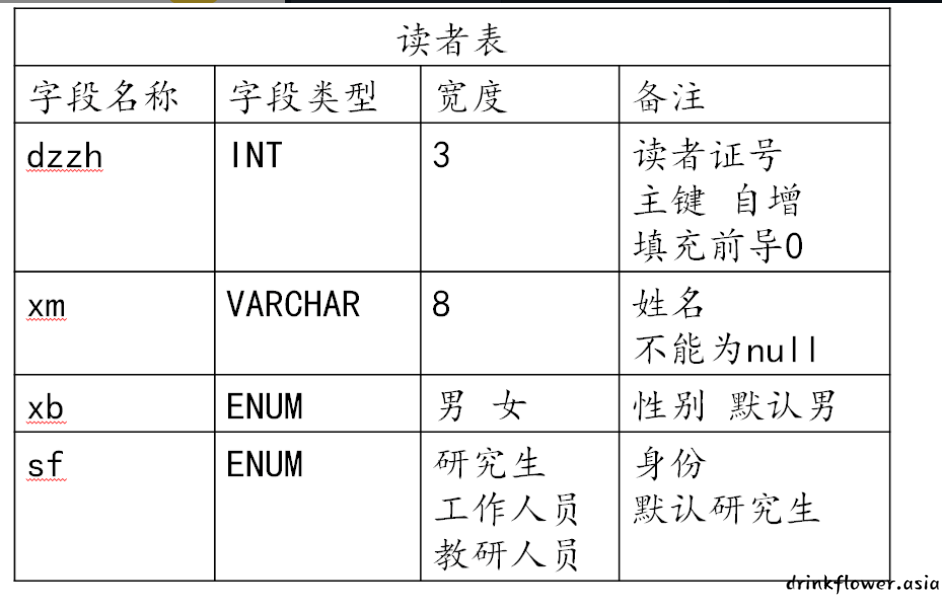
use library;
create table dz(
dzzh int(3) zerofill auto_increment,
xm varchar(8) not null,
xb enum("男","女") default "男",
sf enum("研究生","工作人员","教研人员") default "研究生",
primary key (dzzh)
);
describe dz;- ZEROFILL:表示以零填充方式显示数值。如果该列的值比指定宽度小,则会在数字左侧填充零,以达到指定宽度的效果;
- auto_increment 是 MySQL 数据库中的一个关键字,它用于定义一个自增长列,在每次插入新数据时,该列的值会自动加 1。例如,在使用 auto_increment 属性创建一个整数类型(INT)的列后,在每次向这个表中插入一条新纪录时,数据库会自动将该列的值设置为比上一条记录的值多 1。这样,就可以确保每条记录都有唯一的标识符,且不需要手动输入或指定。
- 当你向一个具有 auto_increment属性的列插入第一条记录时,该列的值会自动设置为起始值。在 MySQL 中,默认情况下,这个起始值是 1。如果你希望自定义起始值,可以使用 AUTO_INCREMENT=n语句,其中 n是你想要的起始值。
- 一个表只能有一个自增长列,并且它必须是主键或唯一索引的一部分。如果使用了auto_increment,那么就需要使用primary key设置该列为主键
第3关:修改数据表名字
修改数据表的名字
修改表名
ALTER TABLE <旧表名> RENAME <新表名> ;alter table `dz` rename to `reader`;
或者
ALTER TABLE dz RENAME TO reader;第4关:在数据表中添加字段
如何在数据表添加字段
添加新的字段
ALTER TABLE <表名> ADD <新字段名> <数据类型> ;
字段数据类型设置规则
没有数量含义的字符编码,例如电话号码,qq号码,设置为可变字符alter table reader add dhhm varchar(11);- 没有数量含义的字符编码就用char型喽
第5关:修改数据表的字段名称
修改字段的名称
ALTER TABLE <表名> CHANGE <旧字段名> <新字段名> <数据类型>; alter table reader change dhhm mobile varchar(11);第6关:修改数据表的字段类型
获取修改数据表的字段
修改字段
ALTER TABLE <表名> MODIFY <字段名> <数据类型>;alter table reader modify dhhm varchar(12);第7关:删除数据表的字段
删除数据表的字段
ALTER TABLE <表名> DROP <字段名>alter table reader drop dhhm;第8关:删除数据表
删除数据表
删除数据表
drop table 数据表名
查看数据表
查看数据库的所有数据表
SHOW TABLES;drop table reader;
show tables;第9关:删除数据库
删除数据库
drop database 数据库名
删除数据库是将已经存在的数据库从磁盘空间上清除,清除之后,数据库中的所有数据也将一同被删除。drop database library;
show databases;数据库实验二(一)
第1关:插入数据
根据提示,在右侧编辑器Begin-End处补充代码:
我们为你新建了一个空数据表tb_emp,请你为它同时添加3条数据内容;
空数据表结构如下,注意字段3 为DeptId,倒数第二个字母为大写的i:
需要你同时添加的数据内容为: (注意,是同时插入多条记录)
最终结果会如下图所示: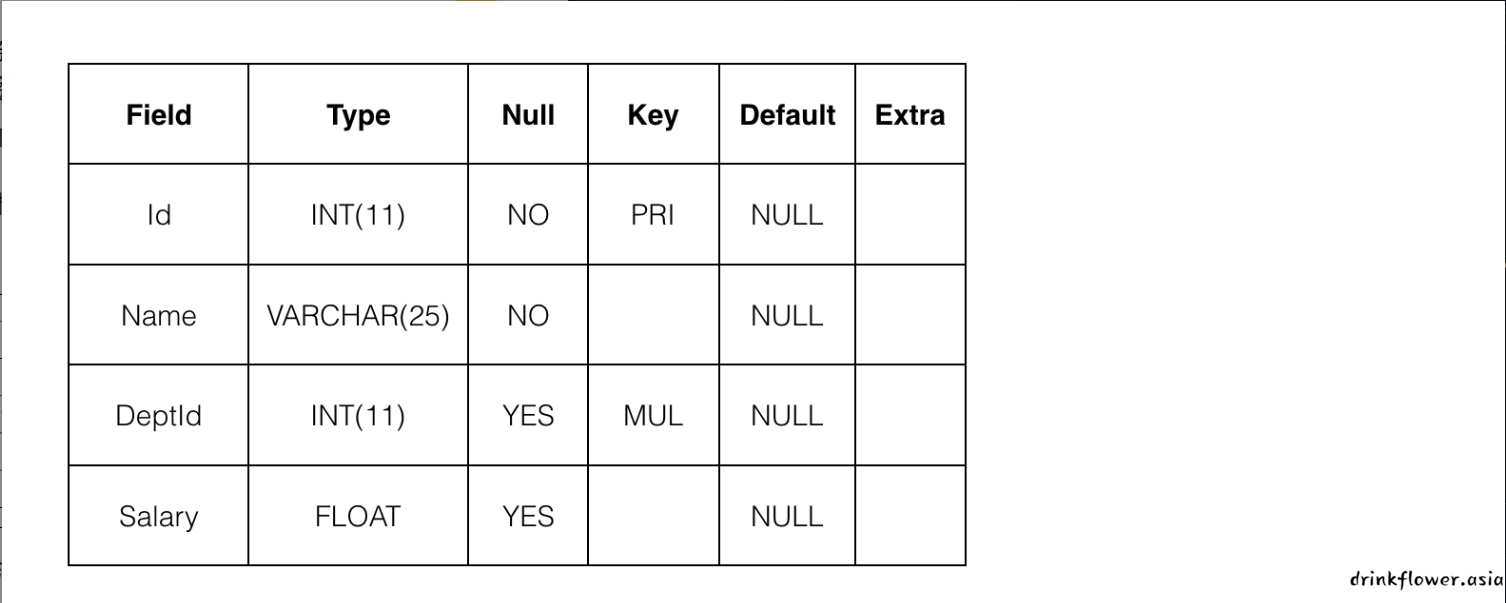
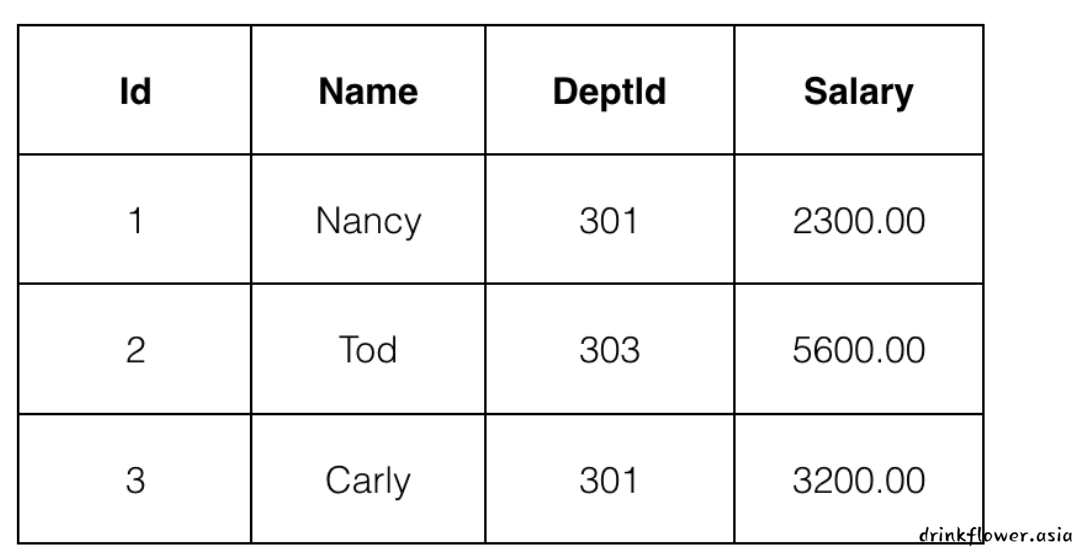
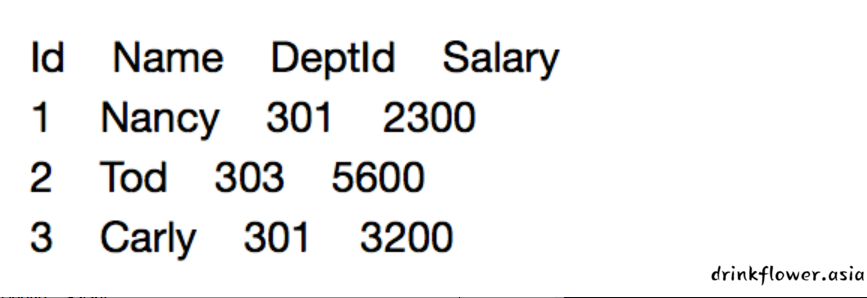
insert into tb_emp(Id,Name,DeptId,Salary) values(1,"Nancy",301,2300.0),(2,"Tod",303,5600.0),(3,"Carly",301,3200.0);- 字段名和表名要么直接写,要么加反引号包裹
第2关:更新数据
根据提示,在右侧编辑器Begin-End处补充代码:
我们为你新建了一个数据表tb_emp,并添加了3条数据内容;
3条数据内容如下表所示:
请你将Carly改为Tracy,相应的,301改为302,3200.00改为4300.00。
注意:字段3为DeptId,倒数第二个字母为大写的i。
我会对你编写的代码进行测试,最终结果会如下图所示: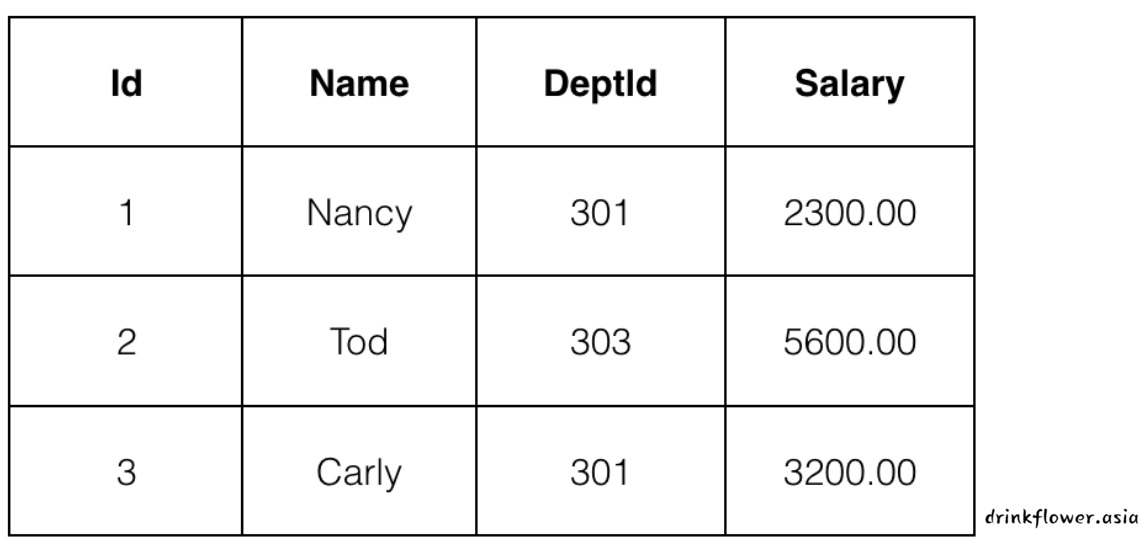

update tb_emp
set name='tracy',DeptId=301,Salary=2300.0
where Id=1;第3关:删除数据
根据提示,在右侧编辑器Begin-End处补充代码:
我们为你新建了一个数据表tb_emp,并添加了3条数据内容;
3条数据内容如下表所示:
请你将Salary大于3000的数据行删除。
我会对你编写的代码进行测试,最终结果会如下图所示: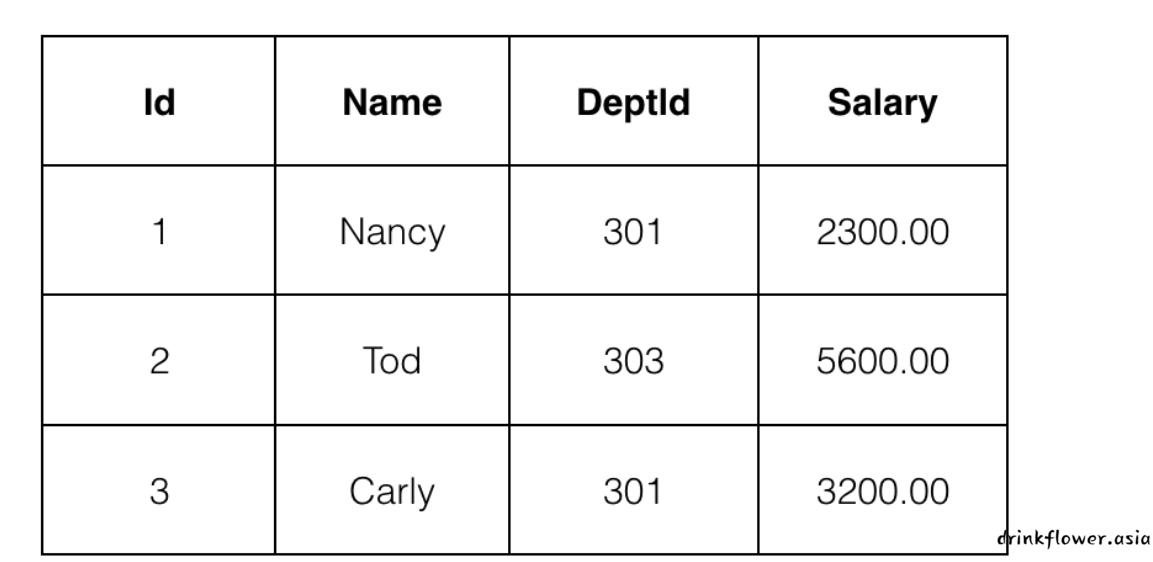

delete from tb_emp where Salary>3000;第4关:应用题
本关任务:给定一张 tb_Salary 表,如下所示,有 m = 男性 和 f = 女性的值。交换所有的 f 和 m 值(例如,将所有 f 值更改为 m,反之亦然)。
id name sex salary
1 Elon f 7000
2 Donny f 8000
3 Carey m 6000
4 Karin f 9000
5 Larisa m 5500
6 Sora m 500
要求只使用一句更新update语句,且不允许含有任何select语句完成任务。
预期输出:
+----+--------+-----+--------+
| id | name | sex | salary |
+----+--------+-----+--------+
| 1 | Elon | m | 7000 |
| 2 | Donny | m | 8000 |
| 3 | Carey | f | 6000 |
| 4 | karin | m | 9000 |
| 5 | Larisa | f | 5500 |
| 6 | Sora | f | 500 |
+----+--------+-----+--------+update tb_emp
set sex= case when sex='m' then 'f' else 'm' end;- 虽然下面这样写很容易懂,但是不被允许,一个意思
update tb_Salary
case when sex='m' then set sex='f' else set sex='m' end;数据库实验二(二)
第1关:基本查询语句
根据提示,在右侧编辑器Begin-End处补充代码:
我们为你新建了一个数据表tb_emp,结构如下:
请你查询字段Name和Salary的内容;
请你查询整张表的内容。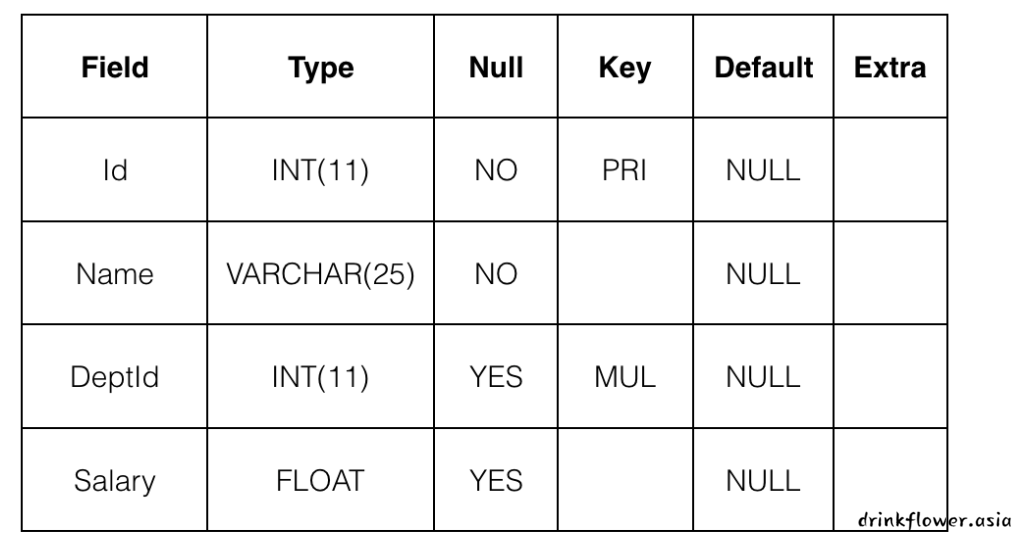
select Name,Salary from tb_emp;
select * from tb_emp;第2关:带 IN 关键字的查询
编程要求
根据提示,在右侧编辑器Begin-End处补充代码:
我们为你新建了一个数据表tb_emp,结构如下:
请你查询当Id不等于1时,字段Name和Salary的内容;
测试说明
我会对你编写的代码进行测试,最终结果会如下图所示:

select Name,Salary from tb_emp where Id not in (1);第3关:带 BETWEEN AND 的范围查询
编程要求
根据提示,在右侧编辑器Begin-End处补充代码:
我们为你新建了一个数据表tb_emp,结构如下:
请你查询当字段Salary范围在3000~5000时,字段Name和Salary的内容。
测试说明
我会对你编写的代码进行测试,最终结果会如下图所示:

select Name,Salary from tb_emp where Salary between 3000 and 5000;第4关:带 LIKE 的字符匹配查询
编程要求
根据提示,在右侧编辑器Begin-End处补充代码;
我们为你新建了一个数据表tb_emp,结构如下:
请你查询所有Name以字母C为起始的员工的Name和Salary的内容;
测试说明
我会对你编写的代码进行测试,最终结果会如下图所示: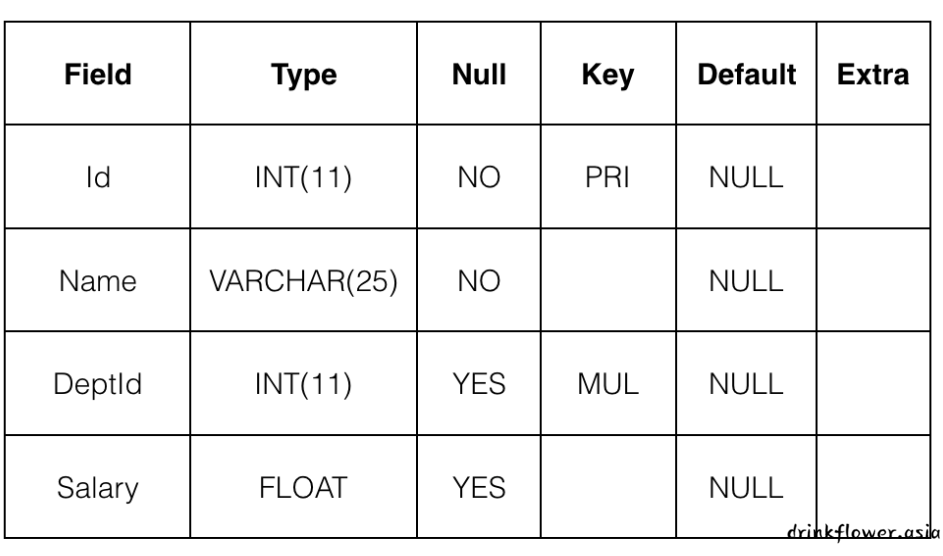
select Name,Salary from tb_emp where Name like 'C%';第5关:带 AND 与 OR 的多条件查询
编程要求
根据提示,在右侧编辑器Begin-End处补充代码:
我们为你新建了一个数据表tb_emp,内容如下:
结构如下:
使用关键字AND返回数据表中字段DeptId为301并且薪水大于3000的所有字段的内容,其中DeptId的倒数第二个字母为i的大写;
使用关键字IN返回数据表中字段DeptId为301和303的所有字段的内容。
测试说明
我会对你编写的代码进行测试,最终结果会如下图所示: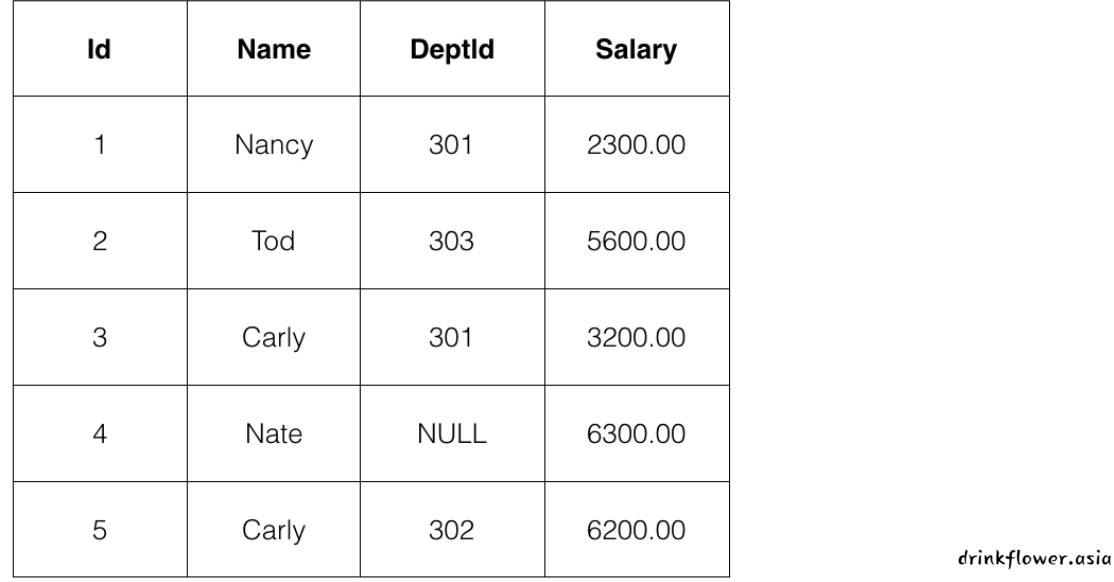

select * from tb_emp where DepID=310 and Salary>3000;
select * from tb_emp where DepID in (310) and Salary>3000;第6关:对查询结果进行排序
编程要求
在右侧编辑器Begin-End处补充代码,查询学生成绩表中1班同学的所有信息并以成绩降序的方式显示结果。
我们已经为你提供了学生成绩表:
tb_score表数据:
stu_id class_id name score
1 2 Jack 81
2 1 David 74
3 1 Mason 92
4 2 Ethan 89
5 1 Gina 65
测试说明
平台会对你编写的代码进行测试:
预期输出:
stu_id class_id name score
3 1 Mason 92
2 1 David 74
5 1 Gina 65select * from tb_score where class_id=1 order by score desc;第7关:分组查询
在右侧编辑器Begin-End处补充代码,对班级表中的班级名称进行分组查询。
我们已经为你提供了班级表信息:
tb_class表数据:
stu_id class_id name
1 367 Jack
2 366 David
3 366 Mason
4 367 Ethan
5 366 Gina
测试说明
平台会对你编写的代码进行测试:
预期输出:
stu_id class_id name
2 366 David
1 367 Jackselect * from tb_class group by class_id;数据库实验三
第1关:查询每个学生的选修的课程信息
任务描述
已知学生表(s)的部分数据如下:
,
期中sno表示学号,sn表示姓名,sex表示性别,age表示年龄,maj表示专业,dept表示学院。
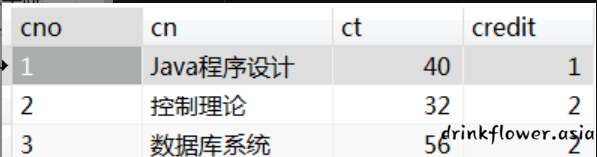
课程表(c)的部分数据如下:
,
期中cno表示课程号,cn表示课程名称,ct表示课时,credit表示学分。
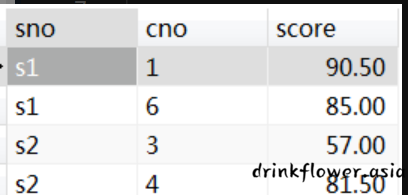
选修表sc的部分数据如下:
,
期中sno表示学号,cno表示课程号,score表示成绩。
本关任务:查询每个学生的选修的课程信息,显示sno、sn、cn、ct,并按ct降序排列。
SELECT s.sno, s.sn, c.cn, c.ct
FROM s INNER JOIN sc ON s.sno = sc.sno
INNER JOIN c ON sc.cno = c.cno
ORDER BY c.ct DESC;- 可以使用表名.列名,甚至可以使用库名.表名.列名
- inner join内连接的解释如下
假设有以下两个表:
表 s(学生表):
sno sn
1 Alice
2 Bob
3 Charlie
表 sc(选课表):
sno cno
1 C001
1 C002
2 C002
3 C003
现在我们使用 INNER JOIN 将表 s 和表 sc 进行连接,并选择 sno、sn 和 cno 字段:
sql
SELECT s.sno, s.sn, sc.cno
FROM s
INNER JOIN sc ON s.sno = sc.sno;
连接条件为 s.sno = sc.sno,表示只选择学生和选课表中学号相等的行进行连接。执行以上查询后,结果集如下:
sno sn cno
1 Alice C001
1 Alice C002
2 Bob C002
3 Charlie C003
可以看到,INNER JOIN 后的结果集中只包含了满足连接条件的行,而没有出现表中的其他行。这是因为只有那些学号在两个表中都存在的学生才会被返回。
因此,通过 INNER JOIN 连接后,SELECT 语句的结果会根据连接条件的匹配情况发生改变。在上述示例中,连接后的结果集比之前的结果集增加了 cno 字段,并且只包含满足连接条件的行。第2关:查询选修了“数据结构”课程的学生名单
任务描述
已知学生表(s)的部分数据如下:
,
期中sno表示学号,sn表示姓名,sex表示性别,age表示年龄,maj表示专业,dept表示学院。
课程表(c)的部分数据如下:
,
期中cno表示课程号,cn表示课程名称,ct表示课时,credit表示学分。
选修表sc的部分数据如下:
,
期中sno表示学号,cno表示课程号,score表示成绩。
本关任务:
查询选修了“数据结构”课程的学生名单,显示sno,sn,按学号升序排序。
SELECT s.sno, s.sn
FROM s
INNER JOIN sc ON s.sno = sc.sno
INNER JOIN c ON sc.cno = c.cno
WHERE c.cn = '数据结构'
ORDER BY s.sno ASC;第3关:查询“数据结构”课程的学生成绩单
任务描述
已知学生表(s)的部分数据如下:
,
期中sno表示学号,sn表示姓名,sex表示性别,age表示年龄,maj表示专业,dept表示学院。
课程表(c)的部分数据如下:
,
期中cno表示课程号,cn表示课程名称,ct表示课时,credit表示学分。
选修表sc的部分数据如下:
,
期中sno表示学号,cno表示课程号,score表示成绩。
本关任务:
查询“数据结构”课程的学生成绩单,显示sno,sn,score,按成绩降序排列。
SELECT s.sno, s.sn, sc.score
FROM s
INNER JOIN sc ON s.sno = sc.sno
INNER JOIN c ON sc.cno = c.cno
WHERE c.cn = '数据结构'
ORDER BY sc.score DESC;第4关:查询每门课程的选课人数
任务描述
已知学生表(s)的部分数据如下:
,
期中sno表示学号,sn表示姓名,sex表示性别,age表示年龄,maj表示专业,dept表示学院。
课程表(c)的部分数据如下:
,
期中cno表示课程号,cn表示课程名称,ct表示课时,credit表示学分。
选修表sc的部分数据如下:
,
期中sno表示学号,cno表示课程号,score表示成绩。
本关任务:
查询每门课程的选课人数,以中文显示课程号、课程名称、选课人数,没有学生选的课程也要显示,按课程号升序排列。(用外连接)。
SELECT c.cno AS 课程号, c.cn AS 课程名称, COUNT(sc.sno) AS 选课人数
FROM c
LEFT JOIN sc ON c.cno = sc.cno
GROUP BY c.cno, c.cn
ORDER BY c.cno ASC;-
count函数可以计数,但是会导致结果全部在同一行,需要使用group by把数据拆开
-
LEFT join和inner join的区别在于前者在不满足条件的情况下仍然会显示from那张原表,不满足链接的字段被赋值为null,而后者没有满足连接条件的直接在结果中没有
第5关:查询没有选课的学生信息
任务描述
已知学生表(s)的部分数据如下:
,
期中sno表示学号,sn表示姓名,sex表示性别,age表示年龄,maj表示专业,dept表示学院。
课程表(c)的部分数据如下:
,
期中cno表示课程号,cn表示课程名称,ct表示课时,credit表示学分。
选修表sc的部分数据如下:
,
期中sno表示学号,cno表示课程号,score表示成绩。
本关任务:
查询没有选课的学生信息,显示sno,sn,按学号升序排列。
SELECT s.sno, s.sn
FROM s
LEFT JOIN sc ON s.sno = sc.sno
WHERE sc.sno IS NULL
ORDER BY s.sno ASC;- 先连接表,通过null赋值来判断是否存在未选课的学生
- 在SQL中,不能使用等于运算符(=)来比较NULL值,因为NULL表示未知或不存在的值,所以无法确定两个NULL值是否相等。比较NULL值需要用到特殊的运算符"IS NULL"或"IS NOT NULL",表示是否为NULL。因此,在SQL中应该使用"WHERE sc.sno IS NULL"来查找空值,而不是"WHERE sc.sno=NULL"。
第6关:查询学生所学课程平均分超过80分的学生信息
已知学生表(s)的部分数据如下:
,
期中sno表示学号,sn表示姓名,sex表示性别,age表示年龄,maj表示专业,dept表示学院。
课程表(c)的部分数据如下:
,
期中cno表示课程号,cn表示课程名称,ct表示课时,credit表示学分。
选修表sc的部分数据如下:
,
期中sno表示学号,cno表示课程号,score表示成绩。
本关任务:
查询学生所学课程平均分超过80分的学生信息,以中文显示学号、姓名、平均成绩。按学号升序排列。
SELECT s.sno AS 学号, s.sn AS 姓名, AVG(sc.score) AS 平均成绩
FROM s
JOIN sc ON s.sno = sc.sno
GROUP BY s.sno, s.sn
HAVING AVG(sc.score) > 80
ORDER BY s.sno ASC;- WHERE子句:WHERE子句用于在查询开始之前对行进行过滤。它基于列的具体值进行条件判断,并将不满足条件的行排除在结果集之外。WHERE子句通常用于过滤行级别的条件。
- HAVING子句:HAVING子句用于在查询结束后对结果集进行筛选。它基于聚合函数的结果进行条件判断,并将不满足条件的聚合结果排除在结果集之外。HAVING子句通常用于过滤分组级别的条件。
- 假设我们有一个学生成绩表sc,其中包含学生学号(sno)和成绩(score)。如果我们想要筛选出平均成绩大于80的学生,可以使用以下两种方式:
- 使用WHERE子句:
Copy CodeSELECT sno, AVG(score) as avg_score
FROM sc
WHERE score > 80
GROUP BY sno- 这个查询会首先在WHERE子句中过滤掉分数小于等于80的行,然后再计算每个学生的平均成绩。
- 使用HAVING子句:
Copy CodeSELECT sno, AVG(score) as avg_score
FROM sc
GROUP BY sno
HAVING AVG(score) > 80-
这个查询会先计算每个学生的平均成绩,然后在HAVING子句中过滤掉平均成绩小于等于80的学生。
-
总结来说,WHERE子句用于行级别的条件过滤,而HAVING子句用于分组级别的条件过滤。在涉及聚合函数(如AVG、SUM等)并需要对聚合结果进行筛选时,应使用HAVING子句。
-
这里不用where是因为聚合函数不能和where一起用
数据库实验五
第1关:更新学生信息
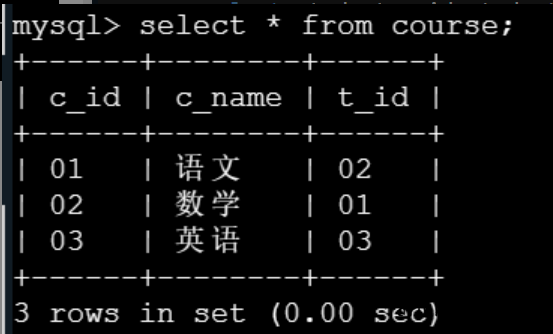
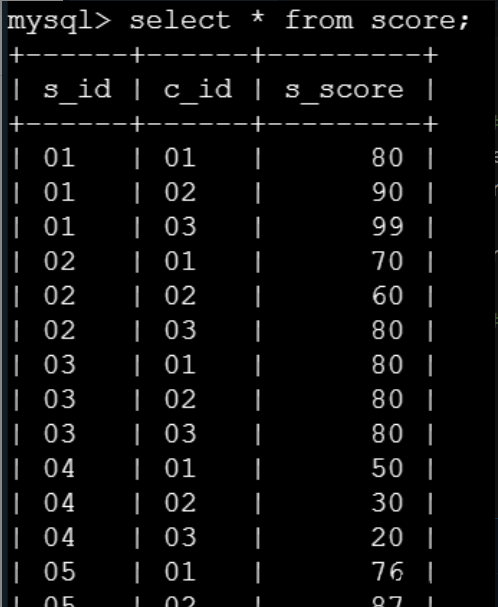
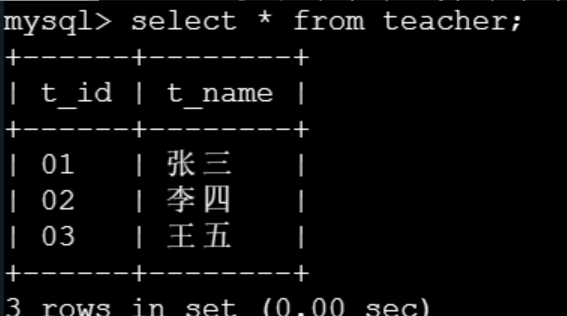
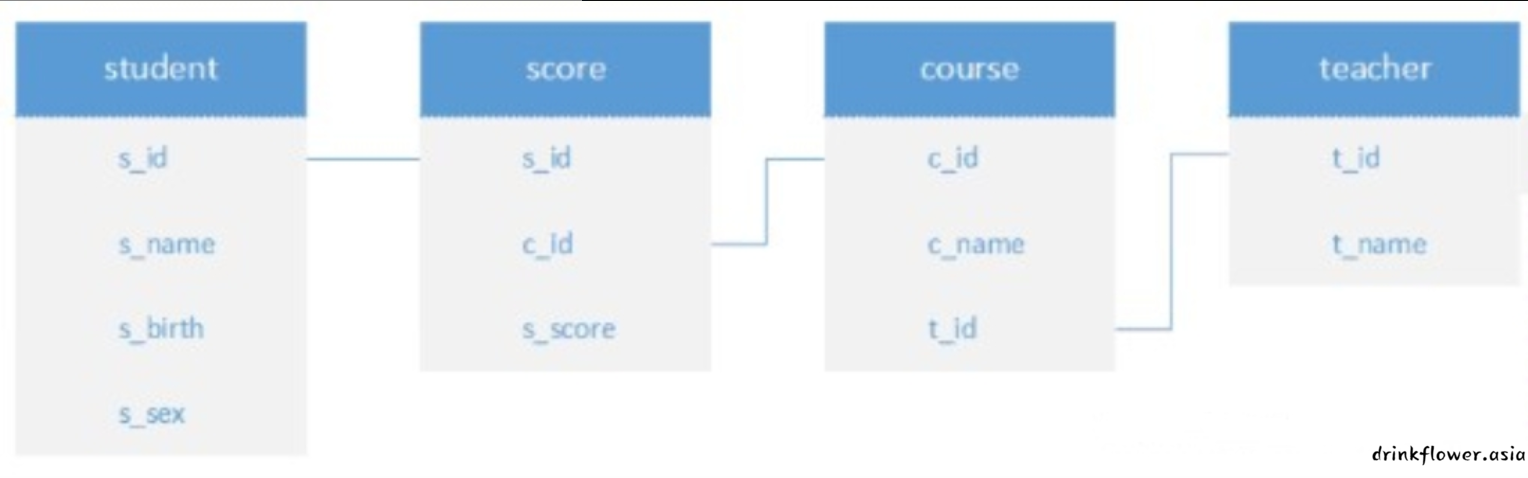
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
学生信息有一个错误,需要更新。学生ID为01的学生的出生日期(s_birth)错误为'2000-05-15',实际应为'2000-04-30'。请更新学生表中的相应记录,并在更新后查询学生ID为01的学生的出生日期。
测试说明
输出:
s_birth
2000-04-30 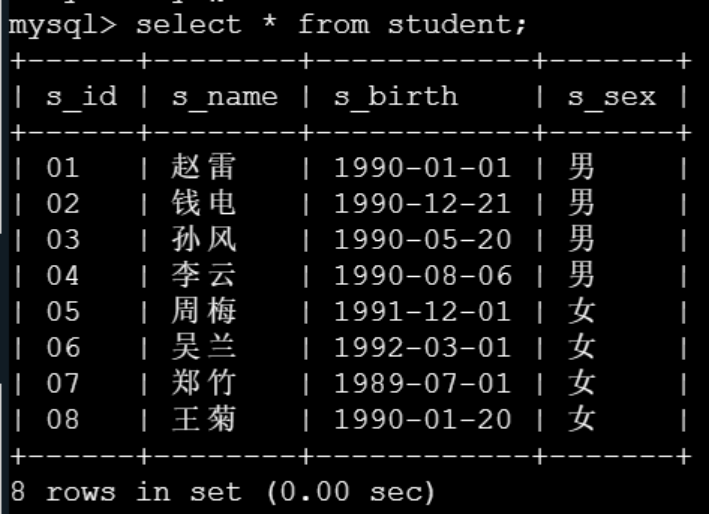
update student set s_birth='2000-04-30'
where s_id='01';
select s_birth from student where s_id='01';第2关:查询课程平均分
任务描述
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
计算课程ID为01的课程的平均成绩。
测试说明
输出:
平均成绩
64.5000
select avg(s_score) as 平均成绩
from score
having c_id='01'第3关:查询"李"姓老师的数量
任务描述
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
查询"李"姓老师的数量。
测试说明
输出:
+-------------+
| cnt_name_li |
+-------------+
| 1 |
+-------------+
select count(t_name) as cnt_name_li from teacher
where t_name like '李%';第4关:查询每门课程被选修的学生数
任务描述
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
题目:查询每门课程被选修的学生数
测试说明
输出:
+------+--------+-------------+
| c_id | c_name | cnt_student |
+------+--------+-------------+
| 1 | 语文 | 6 |
| 2 | 数学 | 6 |
| 3 | 英语 | 6 |
+------+--------+-------------+
select course.c_id,course.c_name,count(score.s_id) as cnt_student
from course
inner join score on score.c_id=course.c_id
group by c_id;第5关:查询学生的总成绩并进行排名
任务描述
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
题目:查询学生的总成绩并进行排名
测试说明
输出:
+------+------+--------+-----------+
| rank | s_id | s_name | sum_score |
+------+------+--------+-----------+
| 1 | 1 | 赵雷 | 269 |
| 2 | 3 | 孙风 | 240 |
| 3 | 2 | 钱电 | 195 |
| 4 | 7 | 郑竹 | 187 |
| 5 | 5 | 周梅 | 163 |
| 6 | 4 | 李云 | 120 |
| 7 | 6 | 吴兰 | 65 |
+------+------+--------+-----------+
set @r:=0;
select @r:=@r+1 as 'rank',sub.id as s_id,sub.name as s_name,sub.su as sum_score
from (
select student.s_id as id,student.s_name as name,sum(score.s_score) as su
from student
inner join score on student.s_id=score.s_id
group by student.s_id
order by sum(score.s_score) desc
) as sub第6关:查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩。
任务描述
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩。
测试说明
输出:
+------+--------+------------+-----------+
| s_id | s_name | cnt_course | sum_score |
+------+--------+------------+-----------+
| 1 | 赵雷 | 3 | 269 |
| 2 | 钱电 | 3 | 195 |
| 3 | 孙风 | 3 | 240 |
| 4 | 李云 | 3 | 120 |
| 5 | 周梅 | 2 | 163 |
| 6 | 吴兰 | 2 | 65 |
| 7 | 郑竹 | 2 | 187 |
| 8 | 王菊 | 0 | 0 |
+------+--------+------------+-----------+
select student.s_id,student.s_name,coalesce(count(score.c_id),0) as cnt_course,coalesce(sum(score.s_score),0) as sum_score
from student
left join score on student.s_id=score.s_id
group by s_id;- coalesce可以给null字段赋初始值
第7关:查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
任务描述
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩。
测试说明
输出:
+------+--------+-----------+
| s_id | s_name | avg_score |
+------+--------+-----------+
| 1 | 赵雷 | 89.67 |
| 2 | 钱电 | 65.00 |
| 3 | 孙风 | 80.00 |
| 5 | 周梅 | 81.50 |
| 7 | 郑竹 | 93.50 |
+------+--------+-----------+
select student.s_id,student.s_name,round(avg(score.s_score),2) as avg_score
from student
inner join score on student.s_id=score.s_id
group by s_id
having avg(score.s_score)>=60;- ROUND()函数是在 SQL 中常用的一个数值函数,用于对数值进行四舍五入。
sqlCopy CodeSELECT ROUND(3.14159); -- 输出: 3
SELECT ROUND(3.14159, 2); -- 输出: 3.14
SELECT ROUND(3.14159, 3); -- 输出: 3.142- 此外,还有一些相关的函数,如 CEILING()(向上取整)和 FLOOR()(向下取整),它们可以根据具体需求对数值进行舍入操作。
第8关:查询学过"张三"老师授课的同学的信息
任务描述
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
查询学过"张三"老师授课的同学的信息
测试说明
输出:
+------+--------+------------+-------+
| s_id | s_name | s_birth | s_sex |
+------+--------+------------+-------+
| 1 | 赵雷 | 1990-01-01 | 男 |
| 2 | 钱电 | 1990-12-21 | 男 |
| 3 | 孙风 | 1990-05-20 | 男 |
| 4 | 李云 | 1990-08-06 | 男 |
| 5 | 周梅 | 1991-12-01 | 女 |
| 7 | 郑竹 | 1989-07-01 | 女 |
+------+--------+------------+-------+
select student.s_id,student.s_name,student.s_birth,student.s_sex
from student
inner join score on score.s_id=student.s_id
inner join course on course.c_id=score.c_id
inner join teacher on teacher.t_id=course.t_id
where t_name='张三';- 这种要根据不显示的信息当作查询条件(位于别的表上面的),就先把表连起来,然后直接给本表添加条件就可以了
第9关:查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
任务描述
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
题目:查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
测试说明
输出:
+------+--------+------------+-------+-----------+
| s_id | s_name | s_birth | s_sex | max_score |
+------+--------+------------+-------+-----------+
| 1 | 赵雷 | 1990-01-01 | 男 | 90 |
+------+--------+------------+-------+-----------+
select student.s_id,student.s_name,student.s_birth,student.s_sex,score.s_score as max_score
from student
inner join score on score.s_id=student.s_id
inner join course on course.c_id=score.c_id
inner join teacher on teacher.t_id=course.t_id
where t_name='张三'
order by s_score desc
limit 0,1;第10关:查询各学生的年龄(周岁)
任务描述
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
题目:查询各学生的年龄(周岁)
按照出生日期来算,当前月日 < 出生年月的月日则,年龄减一
测试说明
输出:
s_id s_name s_birth s_age
01 赵雷 1990-01-01 33
02 钱电 1990-12-21 32
03 孙风 1990-05-20 33
04 李云 1990-08-06 33
05 周梅 1991-12-01 31
06 吴兰 1992-03-01 31
07 郑竹 1989-07-01 34
08 王菊 1990-01-20 33
select student.s_id,student.s_name,student.s_birth,year(curdate())-left(student.s_birth,4)-2*(right(curdate(),5)<right(student.s_birth,5)) as s_age
from student
order by s_id asc;-
字符串的时间可以直接加减,满足格式的时间字符串可以直接使用year()类的函数来提取年月日,也可以使用left和right来提取字符串
-
这里要实现if语句,同时if的结果只用于数学运算,直接使用(right(curdate(),5)<right(student.s_birth,5)),条件成真为1,条件为假为0
-
但是不知道为啥if写不进去
set @q:=0;
select student.s_id, student.s_name, student.s_birth, year(curdate()) - left(student.s_birth, 4) - @q as s_age,if(right(curdate(), 5) < right(student.s_birth, 5),@q:=1,@q:=0)
from student
order by s_id asc;第11关:查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
任务描述
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
题目:查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
测试说明
输出:
+------+--------+-----------+
| s_id | s_name | avg_score |
+------+--------+-----------+
| 4 | 李云 | 40.00 |
| 6 | 吴兰 | 32.50 |
+------+--------+-----------+
select student.s_id,student.s_name,round(avg(score.s_score),2) as avg_score
from student
inner join score on student.s_id=score.s_id
where score.s_score<60
group by student.s_id
having count(*)>=2;- group by之后可以使用count(*)获得重叠的项数,这里使用count来判断是否挂科达到两次以上
第12关:查询各科成绩最高分、最低分和平均分
任务描述
已经建立如下四个表,请根据编程要求完成任务:
student表
,
course表
,
score表
,
teacher表
,
表关系如下:
,
编程要求
题目:查询各科成绩最高分、最低分和平均分,以如下形式显示:
课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
测试说明
输出:
+--------+----------+--------+--------+--------+--------+--------+--------+--------+
| 课程ID | 课程name | 最高分 | 最低分 | 平均分 | 及格率 | 中等率 | 优良率 | 优秀率 |
+--------+----------+--------+--------+--------+--------+--------+--------+--------+
| 1 | 语文 | 80 | 31 | 64.50 | 66.67% | 66.67% | 33.33% | 0.00% |
| 2 | 数学 | 90 | 30 | 72.67 | 83.33% | 16.67% | 66.67% | 16.67% |
| 3 | 英语 | 99 | 34 | 69.33 | 66.67% | 16.67% | 16.67% | 33.33% |
+--------+----------+--------+--------+--------+--------+--------+--
SELECT
course.c_id AS 课程ID,
course.c_name AS 课程name,
MAX(score.s_score) AS 最高分,
MIN(score.s_score) AS 最低分,
round(AVG(score.s_score),2) AS 平均分,
CONCAT(FORMAT((SUM(CASE WHEN score.s_score >= 60 THEN 1 ELSE 0 END) / COUNT(*)) * 100, 2), '%') AS 及格率,
CONCAT(FORMAT((SUM(CASE WHEN score.s_score >= 70 AND score.s_score <= 80 THEN 1 ELSE 0 END) / COUNT(*)) * 100, 2), '%') AS 中等率,
CONCAT(FORMAT((SUM(CASE WHEN score.s_score >= 80 AND score.s_score < 90 THEN 1 ELSE 0 END) / COUNT(*)) * 100, 2), '%') AS 优良率,
CONCAT(FORMAT((SUM(CASE WHEN score.s_score >= 90 THEN 1 ELSE 0 END) / COUNT(*)) * 100, 2), '%') AS 优秀率
FROM course
JOIN score ON course.c_id = score.c_id
GROUP BY course.c_id;- 数据还有问题
第13关:体育馆的人流量
任务描述
本关任务:某市建了一个新的体育馆,每日人流量信息被记录在gymnasium表中:序号 (id)、日期 (date)、 人流量 (visitors_flow)。
请编写一个查询语句,找出人流量处于高峰的记录 id、日期 date 和人流量 visitors_flow,其中高峰定义为前后连续三天人流量均不少于 100。
gymnasium表结构数据如下:
id date visitors_flow
1 2019-01-01 58
2 2019-01-02 110
3 2019-01-03 123
4 2019-01-04 67
5 2019-01-05 168
6 2019-01-06 1352
7 2019-01-07 382
8 2019-01-08 326
9 2019-01-09 99
提示:每天只有一行记录,日期随着 id 的增加而增加。
相关知识
略
编程要求
请仔细阅读右侧代码,根据方法内的提示,在Begin - End区域内进行代码补充。
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
预期输出:
+----+------------+---------------+
| id | date | visitors_flow |
+----+------------+---------------+
| 5 | 2019-01-05 | 168 |
| 6 | 2019-01-06 | 1352 |
| 7 | 2019-01-07 | 382 |
| 8 | 2019-01-08 | 326 |
+----+------------+---------------+