
- 在前面爬虫爬取的情况中,页面都没有制作严格的反爬措施,比如给api添加一些验证,或者使用jsfxxk把关键的代码隐藏起来.selenium针对这样的情况提供了另一种方式
Selenium 有很多功能, 但其核心是 web 浏览器自动化的一个工具集, 它使用最好的技术来远程控制浏览器实例, 并模拟
用户与浏览器的交互。
它允许用户模拟终端用户执行的常见活动;将文本输入到字段中,选择下拉值和复选框,并单击文档中的链接。 它还提供许多
其他控件,比如鼠标移动、任意 JavaScript 执行等等。- 简单来说,selenium可以使用程序模拟人的行为操作浏览器,selenium本身是一个浏览器自动化操作工具,不过这里被用来做爬虫了而已.
环境配置
- 首先需要pip安装,这里建议指定安琥在那个版本,因为最新的selenium已经更新到4.x系列了,但是网上的大多数教程以及本篇都是针对selenium的3.x的教程,这两个大版本的很多语法都是不同的,我的是3.1.1版本
pip install selenium控制版本
pip install selenium==3.1.1- 安装成功后可以使用来查看安装版本
pip show selenium
- python的库有了,不顾浏览器并不认这个,需要driver提供的api实现python程序和浏览器的通信,所以需要下载webdriver驱动,针对每种浏览器和每个版本的webdriver都是不同的,所以先要确定自己的浏览器版本(额,某安全浏览器就算了吧🤣不支持的),比如我的谷歌

- 然后在官网下载对应版本的驱动即可https://sites.google.com/a/chromium.org/chromedriver/downloads
- 其他浏览器也是一样的,把下载的驱动.exe丢到python的script目录下面,比如
C:\Users\wushaofang\AppData\Local\Programs\Python\Python39\Scripts
C:\Users\wushaofang\AppData\Local\Programs\Python\Python39\Lib\site-packages\selenium\webdriver\chrome。- python的路径具体在哪可以看刚才pip show的结果
基本语法
- 用下面的模板可以简单实现访问
from selenium import webdriver
import time
b = webdriver.Chrome()
b.get('https://www.baidu.com')
time.sleep(5)
b.quit()- 这里的quit函数退出了浏览器,其触发条件hi网页完全加载完成,比如网页加载了10秒,然后sleep5秒后才会退出浏览器,类似的函数运行都是这样的机制
定位元素
-
刚才简单实现了打开一个网页和退出,但是实际的工作显然不止于此,我们需要对网页的元素进行操作,比如点击登录按钮,输入密码,或者,获取网页的内容,这样就需要我们定位到某个具体的元素,再队这个元素进行操作
-
一共有7中定位元素的方式,但是我使用下来感觉只有三种方式有用
- find_element_by_class_name
from selenium import webdriver
import time
b = webdriver.Chrome()
b.get('https://www.baidu.com')
driver.find_element_by_id('元素的id')
time.sleep(5)
b.quit()- 一个正常的网页的每个元素都应该有一个独一无二的id,这可以方便通过使用js定位元素,进行一些dom的函数操作,比如这样
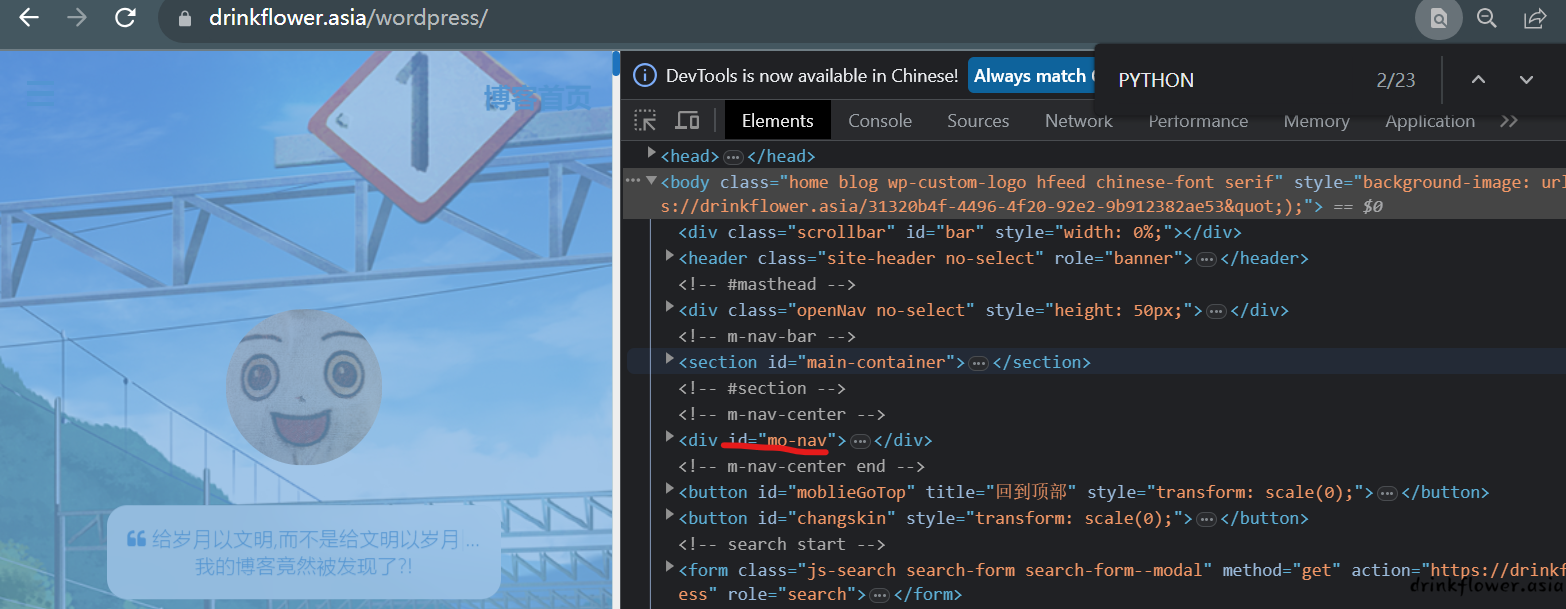
- 但是并不是所有网页都如此规范,可能某些元素是没有id的,在这种情况下就不能使用这种方法了
- find_element_by_xpath
from selenium import webdriver
import time
b = webdriver.Chrome()
b.get('https://www.baidu.com')
driver.find_element_by_xpath('元素的xpath')
time.sleep(5)
b.quit()-
DOM树(Document Object Model Tree)是指HTML或XML文档的逻辑结构在内存中的一种表示方式。当浏览器或解析器读取HTML或XML文档时,它将文档解析成一个层次结构的对象树,这棵树被称为DOM树。
-
XPath 是一种用于在 XML 或 HTML 文档中定位元素的语言。它是一种基于路径表达式的查询语言,可以通过指定元素的层次结构和属性来准确定位DOM树的每一个元素。
-
这种方法是通用的,每个元素是肯定有它的xpath的,xpath也分绝对xpath和相对xpath,这里就全部用绝对路径了
-
获取元素的xpath的方法十分简单,不需要自己去写,只需要在浏览器控制台中选中,然后右键copy即可

- 第三种方法和js操作整合起来放在最后吧
基本操作
- 鼠标点击操作
click()- 比如使用xpath获取一个元素后进行点击
driver.find_element_by_xpath('你的xpath').click()- 模拟按键操作
send_keys("喵喵喵")- 比如使用xpath获取一个元素后进行输入内容
driver.find_element_by_xpath('你的xpath').send_keys("喵喵喵")-
实际上,除了这俩的操作,selenium还有很多更复杂的函数,比如有的网页通过ajax加载,需要准确的确定页面是否加载完成,否则导致获取元素失败,比如需要右键某个元素,然后左键长按某个元素,这些都有相应的函数可以使用
-
这些函数都较为复杂,但是也可以使用,实际上,selenium提供一种更为简单的方法,直接执行js代码
execute_script('你的js代码')- 直接执行js代码比背selenium的函数好用多了,js可以轻松的获取元素,获取元素的值,操作dom树随便改页面元素,除非不会js🐶
- 不过要注意的是如果需要将js执行获得的结果传给python,需要在前面加上return,比如下面这个例子获取了页面的高度
page_height = driver.execute_script('return document.documentElement.scrollHeight;')
print(page_height)