
- 在前面两篇中,我们简单使用了request+re实现了提取网页的静态内容,但是更多的网页是有ajax或者xhr动态生成的, 去许多元素的内容并不会一开始就被写死在html里面,而是html的框架生成后由js写入进去的,这样,前两章的方法就失去作用了
api逆向
-
注意:不是所有api都能给随便爬的,这里只用来做个知识记录,不得用作违法用途
-
比如这是我写的一个页面,我们在页面上看到成都的关键字

- 但是在页面源代码中搜索成都却无法得到具体的内容

- 这是因为我们在html中并没有写入这些数据,而是提前创建了一个tbody的元素占位,它的id是showfilebody
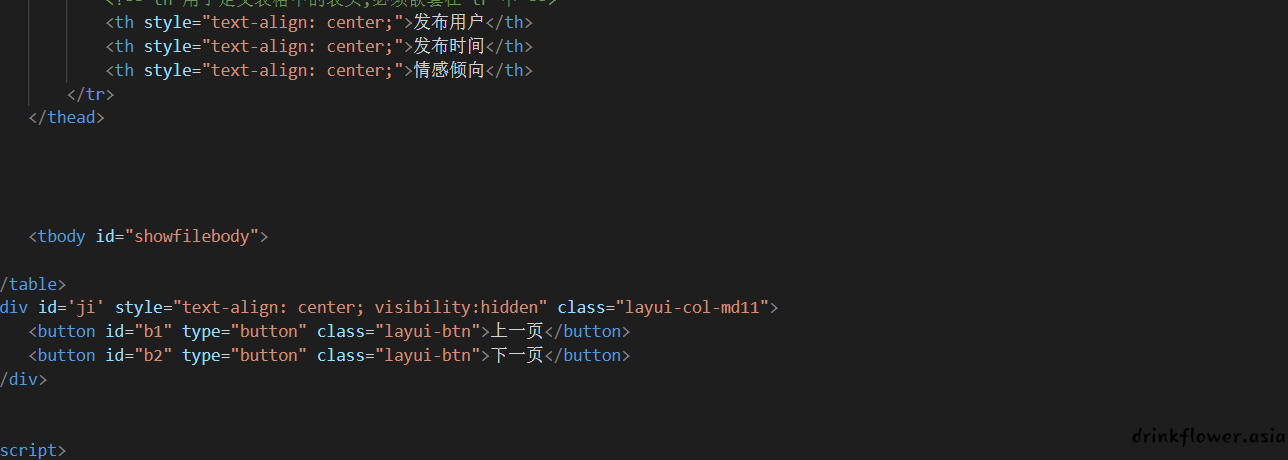
- 那么数据是如何展示的呢?我们通过ajax异步请求了后端的api,然后重写拥有showfilebody的tbody的元素内容(innerHTML)
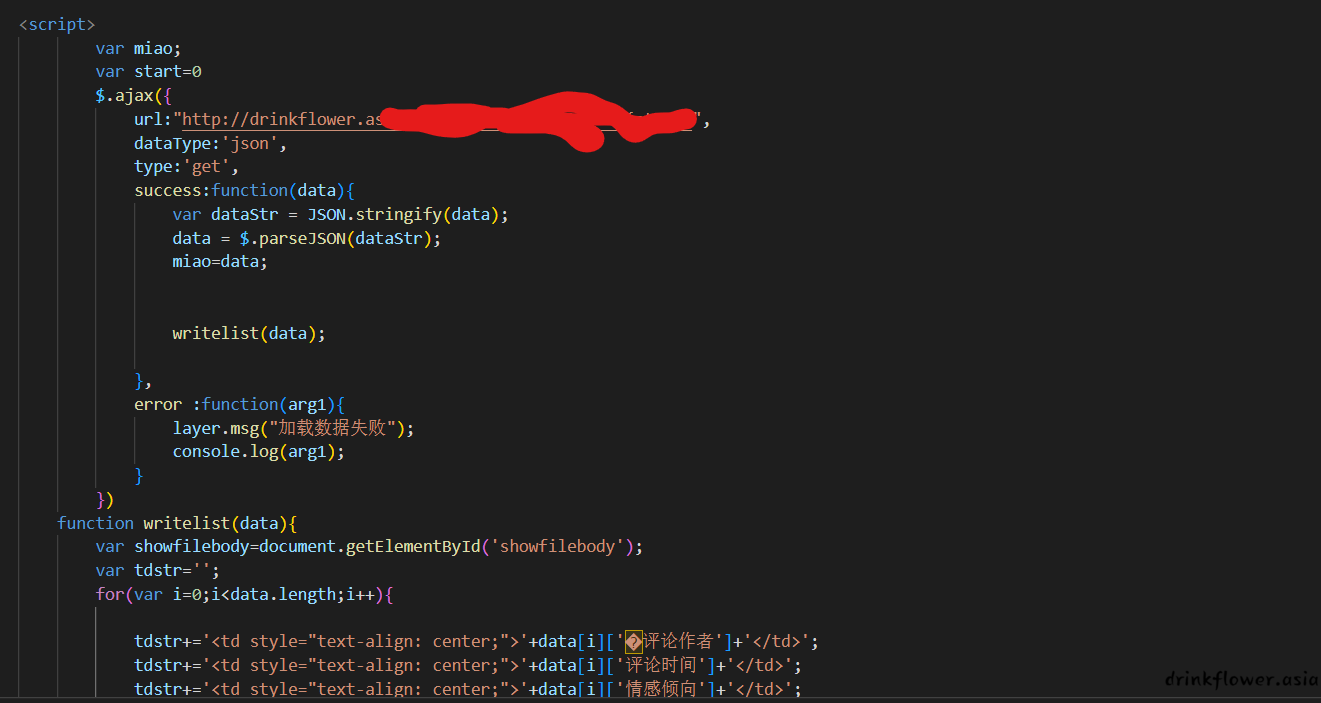
-
既然明白了原理,那么想要这种动态页面的数据就很简单了,只需要找出后端的api就行了,在一些较为困难的情况下,我们需要读原网页的js代码,理清逻辑,不过更多情况下我们可以通过下面的方法轻松的找到后端的api
-
先打开控制台,选择网络
- 然后ctrl+f搜索关键字,点击搜索结果
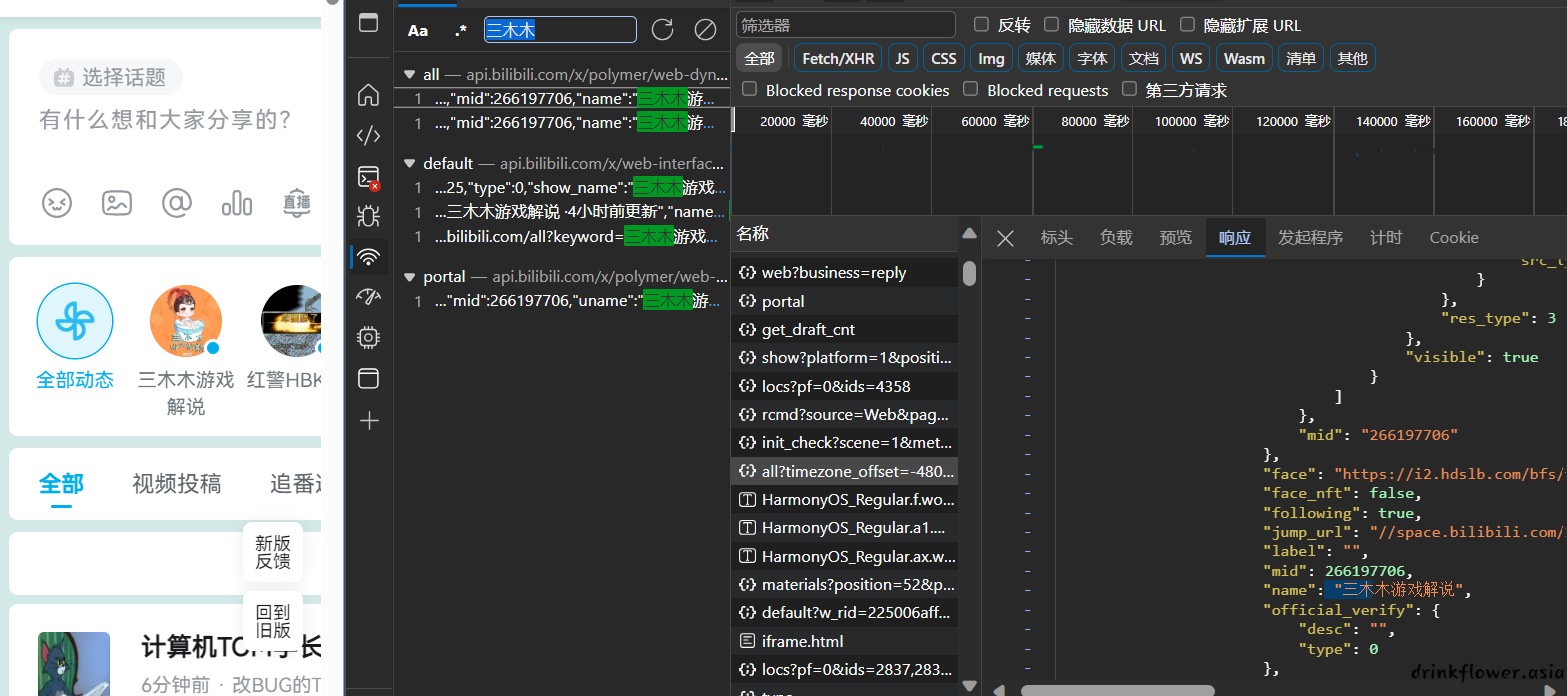
- 这样就能定位到api的具体请求了,可以看到,这个api返回了动态更新的所有json数据
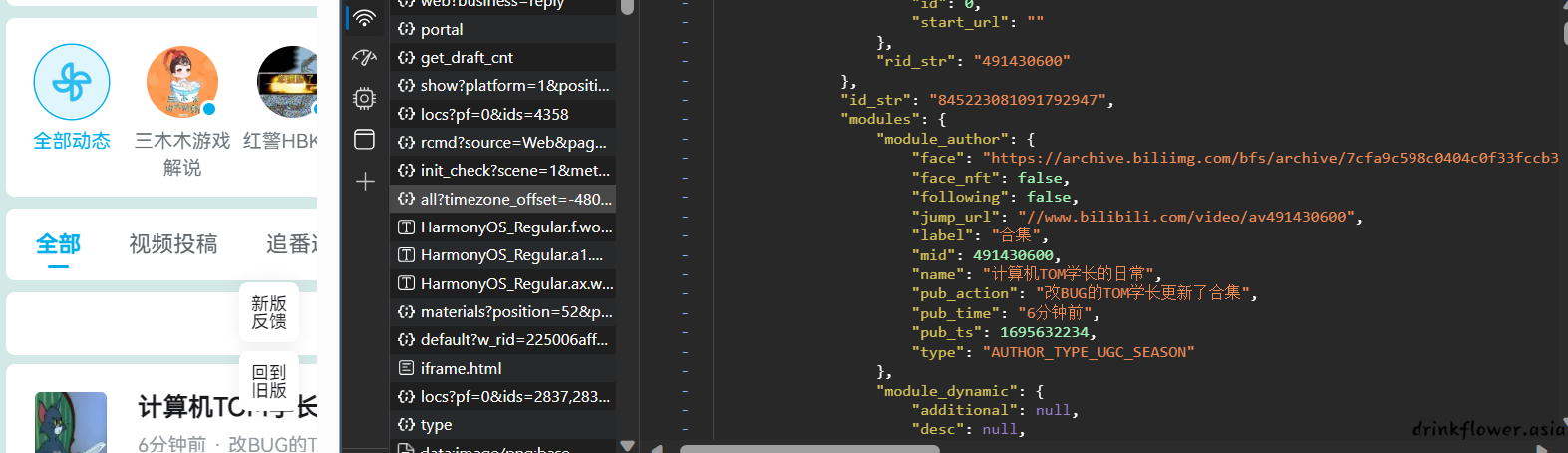
- 点击标头,或者header来查看这个请求的具体url
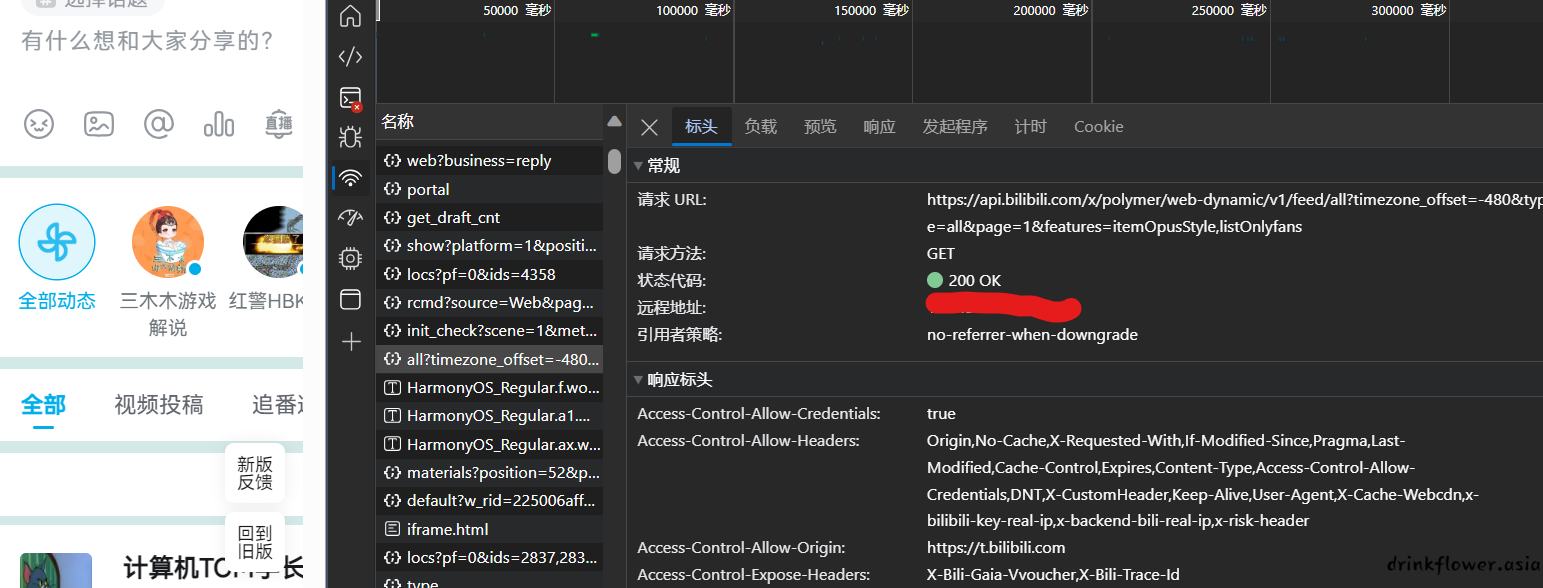
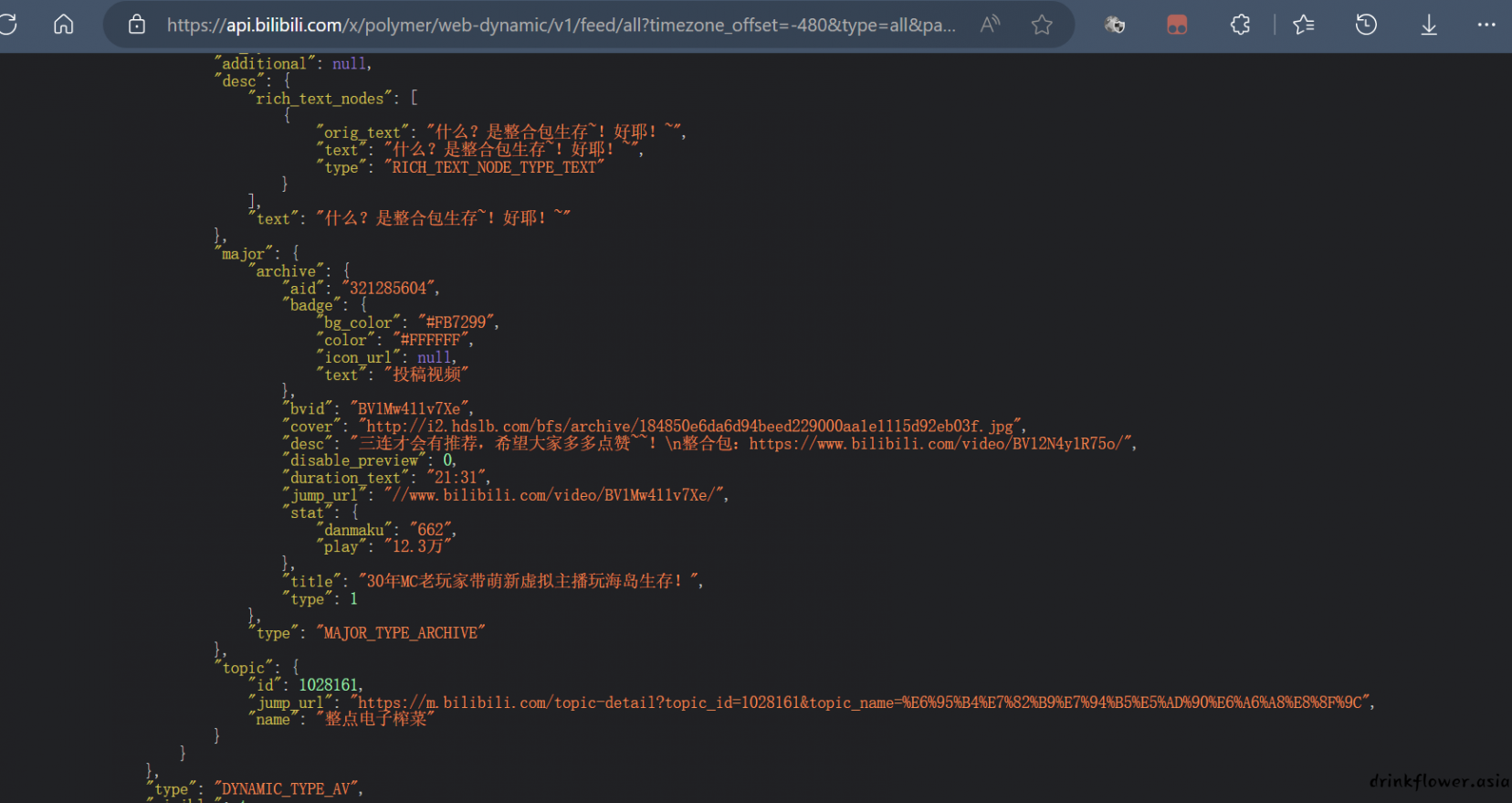
- 然后我们自己访问这个api,发现成功拿到数据,然后编写爬虫爬取这个api并且进行数据处理即可
伪造header
- 对于上面的情况,有的时候api找到之后访问不了,或者本来页面就需要登录,这时候就需要改一下header了

(像这里就有个jwt的验证,不验证是进不去的)
- 我们在request请求的时候,把刚才的通过控制台找到的header带上,即可访问成功
headers = {
'Accept':'*/*',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Authorization':'xxx',
'Content-Type':'application/json',
'Host':'xxx',
'Origin':'xxx',
'Referer':'xxx',
'Sdp-App-Session':'session',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
aim = requests.get('xxx',headers=headers)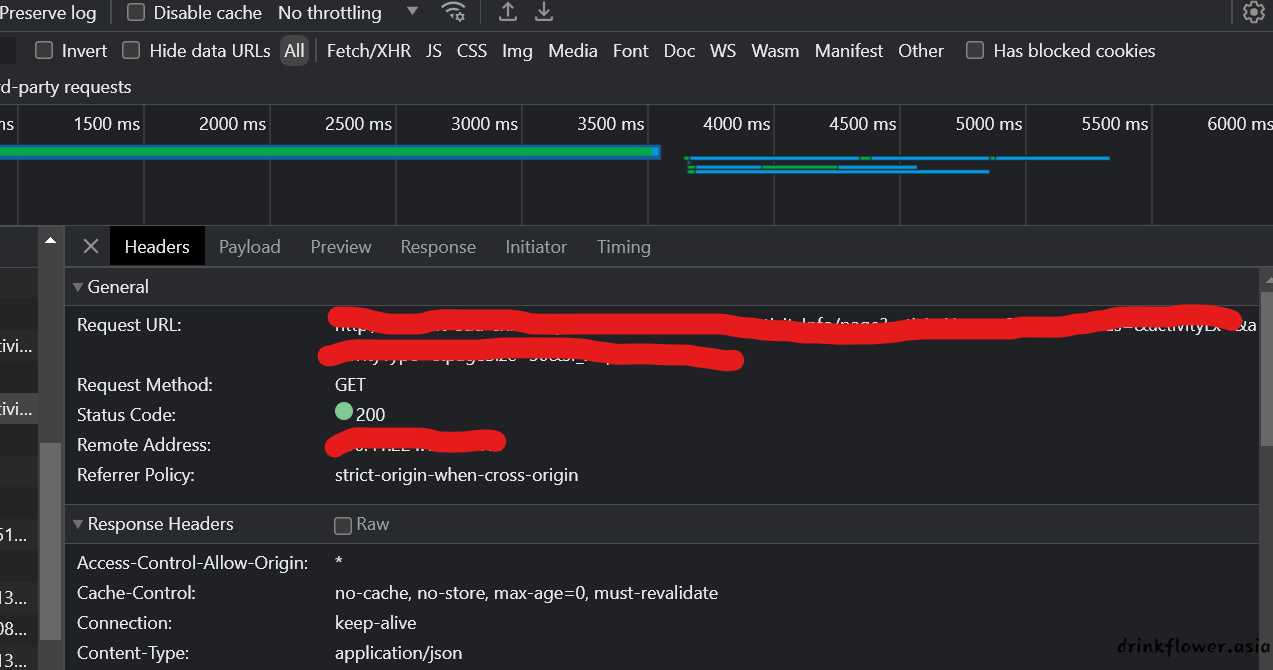
- 其实针对这个网站,可以测试出来控制登录的有Authorization字段和Sdp-App-Session字段,Authorization是一个jwt的token,解一下可以知道这个token的有效期是一天,所以如果要写爬虫,每隔一天就要换一次这俩参数