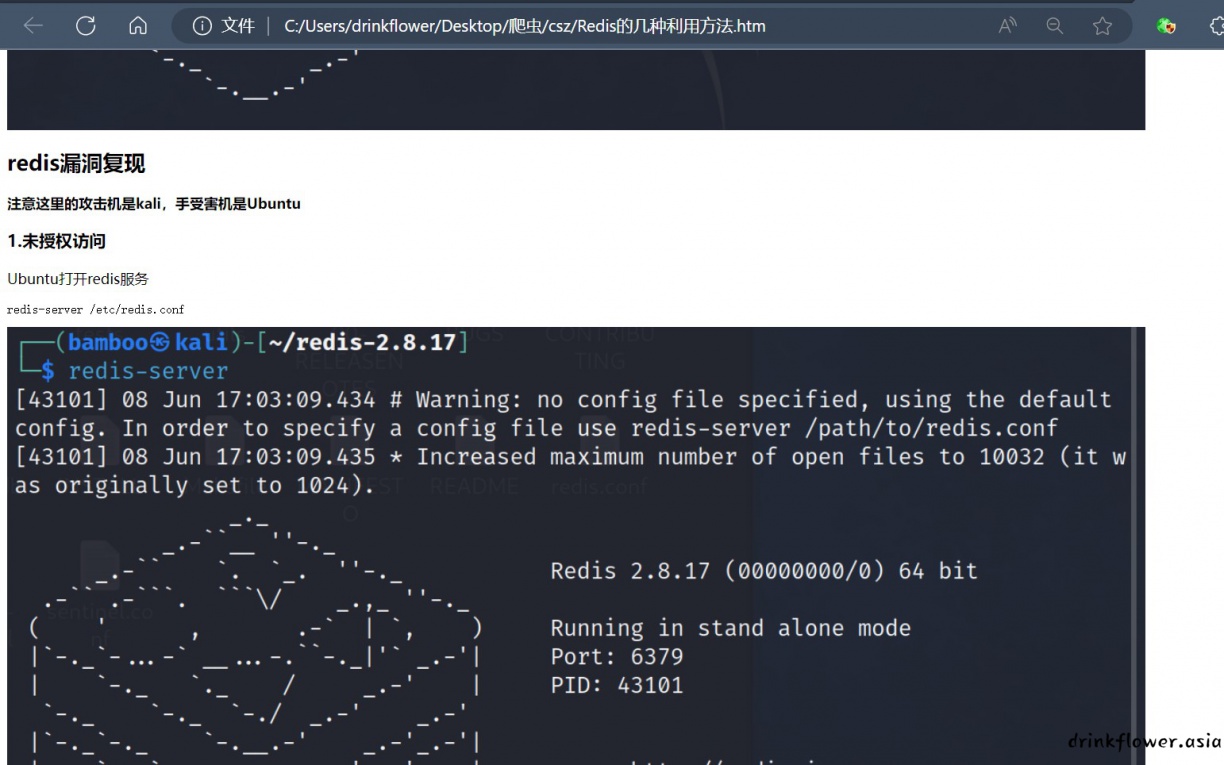
- 本篇建立在前面几篇PYTHON爬虫基础系列报告的基础上,只使用了requests+正则实现了最基本的功能
- 这四个爬虫爬的是hxd的博客,也都是告知了的.如果爬取其他站点要注意不要违法哦🐶
baicany
import re
from weakref import proxy
import requests
import logging
import time
s = requests.Session()
logging.captureWarnings(True)
def find(pattern,input_string):
pattern = pattern
input_string=input_string
match = re.search(pattern, input_string, re.DOTALL)
if match:
return match.group(1)
else:
return None
def findall(pattern,input_string):
pattern = pattern
matches = re.findall(pattern, input_string)
return matches
data = {'name': 'germey', 'age': '25'}
headers = {
'Cookie': '',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
#r = s.post('https://baicany.github.io', headers=headers,params=data,verify=False)
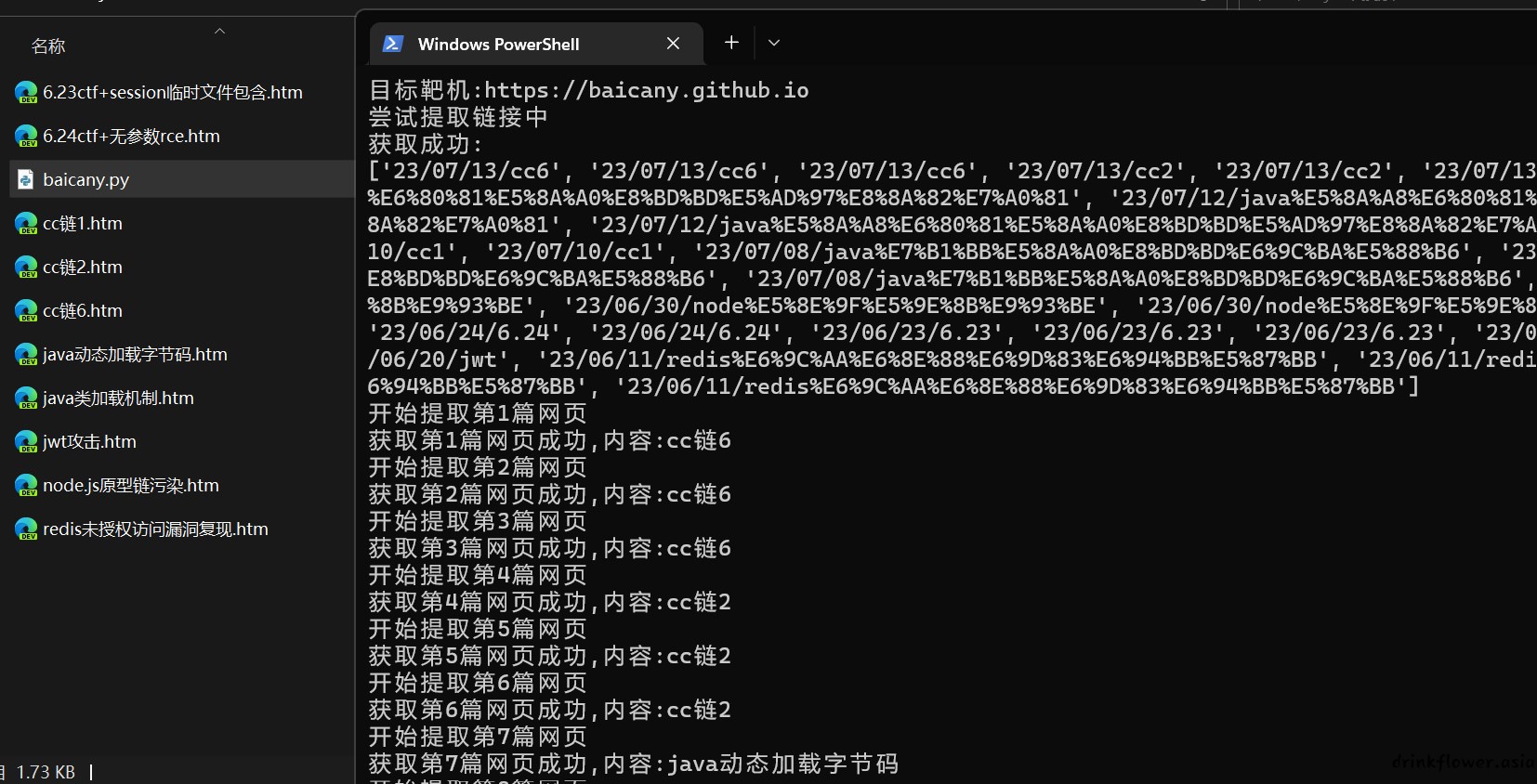
print("目标靶机:https://baicany.github.io")
print("尝试提取链接中")
try:
aim = s.get('https://baicany.github.io')
urls=findall(r"/20(.*?)/\"",aim.text)
# urls = extract_strings(aim.text)
print("获取成功:")
print(urls)
except:
print("连接失败,请检查网络")
time.sleep(100000)
if len(urls) == 0:
print('提取失败,请联系作者')
time.sleep(100000)
count=1
for url in urls:
print("开始提取第%d篇网页"%count)
fakeblog = s.get('https://baicany.github.io/20'+url)
title=find(r'<title itemprop="name">(.*?) | baicany</title>',fakeblog.text)
content=find(r"<div class=\"entry-content\">(.*?)<!-- \.entry-content -->",fakeblog.text)
f = open(title+".htm",'w', encoding='utf-8')
f.write(content)
f.close()
print("获取第%d篇网页成功,内容:%s"%(count,title))
count=count+1

liberator
import re
from weakref import proxy
import requests
import logging
import time
s = requests.Session()
logging.captureWarnings(True)
def find(pattern,input_string):
pattern = pattern
input_string=input_string
match = re.search(pattern, input_string, re.DOTALL)
if match:
return match.group(1)
else:
return None
def findall(pattern,input_string):
pattern = pattern
matches = re.findall(pattern, input_string)
return matches
def replace(pattern,input_string, replacement):
pattern = pattern
replaced_string = re.sub(pattern, replacement, input_string, flags=re.DOTALL)
return replaced_string
data = {'name': 'germey', 'age': '25'}
proxies = {
'http': ''
}
headers = {
'Cookie': '',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
#r = s.post('https://yyb20040616.github.io/archives/', headers=headers,params=data,sverify=False)
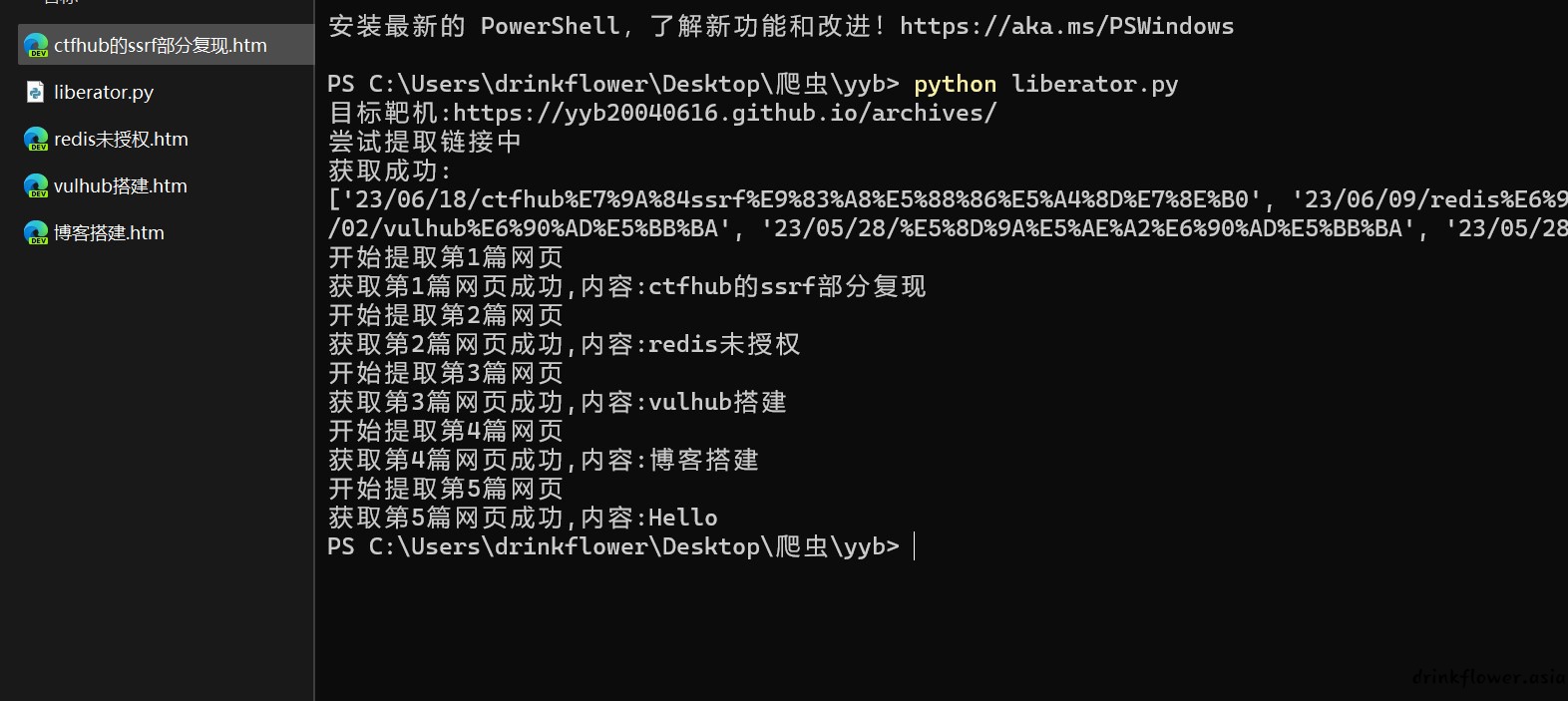
print("目标靶机:https://yyb20040616.github.io/archives/")
print("尝试提取链接中")
try:
aim = s.get('https://yyb20040616.github.io/archives/')
urls=findall(r"/20(.*?)/\"",aim.text)
# urls = extract_strings(aim.text)
print("获取成功:")
print(urls)
except:
print("连接失败,请检查网络")
time.sleep(100000)
if len(urls) == 0:
print('提取失败,请联系作者')
time.sleep(100000)
count=1
for url in urls:
print("开始提取第%d篇网页"%count)
fakeblog = s.get('https://yyb20040616.github.io/20'+url)
title=find(r'<title>(.*?) | liberator</title>',fakeblog.text)
if title==None:
title=find(r'<h2 >(.*?)</h2>',fakeblog.text)
content=find(r'<div class="post-body" itemprop="articleBody">(.*?)<footer class="post-footer">',fakeblog.text)
imgs=findall(r'<img src="(.*?)">',content)
for img in imgs:
img=r'<img src="https://yyb20040616.github.io'+img+'">'
content=replace(r'<img src="(.*?)">',content,img)
if(find(r'<p>(.*?)</p>',content))==None:
print("内容无效")
count=count+1
continue
f = open(title+".htm",'w', encoding='utf-8')
f.write(content)
f.close()
print("获取第%d篇网页成功,内容:%s"%(count,title))
count=count+1

luna
import re
from weakref import proxy
import requests
import logging
import time
s = requests.Session()
logging.captureWarnings(True)
def find(pattern,input_string):
pattern = pattern
input_string=input_string
match = re.search(pattern, input_string, re.DOTALL)
if match:
return match.group(1)
else:
return None
def findall(pattern,input_string):
pattern = pattern
matches = re.findall(pattern, input_string)
return matches
def replace(pattern,input_string, replacement):
pattern = pattern
replaced_string = re.sub(pattern, replacement, input_string, flags=re.DOTALL)
return replaced_string
data = {'name': 'germey', 'age': '25'}
headers = {
'Cookie': '',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
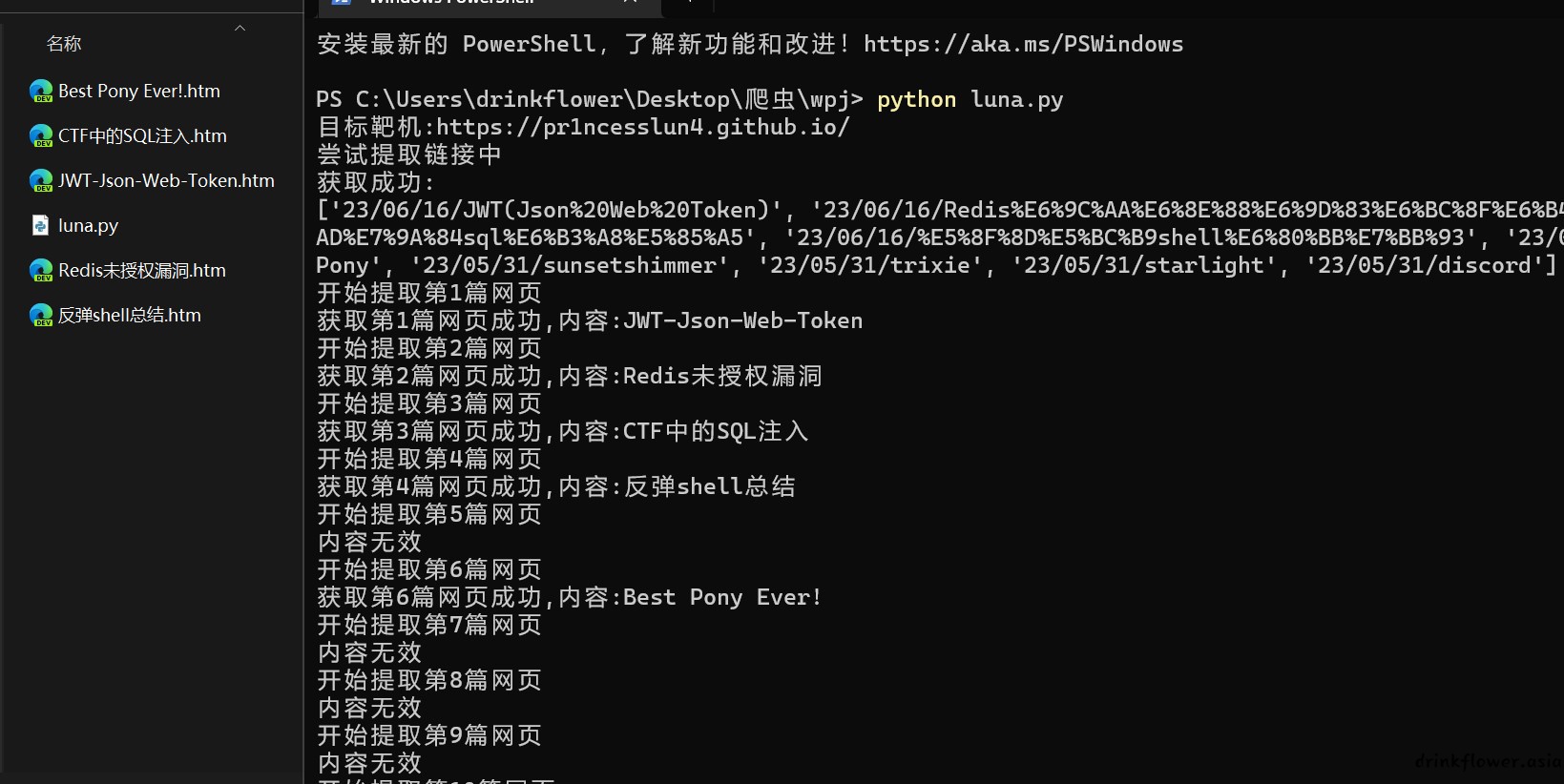
#r = s.post('https://pr1ncesslun4.github.io/', headers=headers,params=data,sverify=False)
print("目标靶机:https://pr1ncesslun4.github.io/")
print("尝试提取链接中")
try:
aim = s.get('https://pr1ncesslun4.github.io/')
urls=findall(r"/20(.*?)/\"",aim.text)
# urls = extract_strings(aim.text)
print("获取成功:")
print(urls)
except:
print("连接失败,请检查网络")
time.sleep(100000)
if len(urls) == 0:
print('提取失败,请联系作者')
time.sleep(100000)
count=1
for url in urls:
print("开始提取第%d篇网页"%count)
fakeblog = s.get('https://pr1ncesslun4.github.io//20'+url)
title=find(r'<h2 id="(.*?)">',fakeblog.text)
if title==None:
title=find(r'<h2 >(.*?)</h2>',fakeblog.text)
content=find(r'<!-- Post -->(.*?)<!-- Post Comments -->',fakeblog.text)
content=replace(r'/../images/',content,r'https://pr1ncesslun4.github.io/images/')
if(find(r'<p>(.*?)</p>',content))==None:
print("内容无效")
count=count+1
continue
f = open(title+".htm",'w', encoding='utf-8')
f.write(content)
f.close()
print("获取第%d篇网页成功,内容:%s"%(count,title))
count=count+1

bamboo
import re
from weakref import proxy
import requests
import logging
import time
s = requests.Session()
logging.captureWarnings(True)
def find(pattern,input_string):
pattern = pattern
input_string=input_string
match = re.search(pattern, input_string, re.DOTALL)
if match:
return match.group(1)
else:
return None
def findall(pattern,input_string):
pattern = pattern
matches = re.findall(pattern, input_string)
return matches
def replace(pattern,input_string, replacement):
pattern = pattern
replaced_string = re.sub(pattern, replacement, input_string, flags=re.DOTALL)
return replaced_string
data = {'name': 'germey', 'age': '25'}
headers = {
'Cookie': '',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
#r = s.post('https://baicany.github.io', headers=headers,params=data,sverify=False)
print("目标靶机:https://www.bamboo22.top")
print("尝试提取链接中")
try:
aim = s.get('https://www.bamboo22.top',headers=headers,proxies=proxies)
urls=findall(r'',aim.text)
# urls = extract_strings(aim.text)
print("获取成功:")
print(urls)
except:
print("连接失败,请检查网络")
time.sleep(100000)
if len(urls) == 0:
print('提取失败,请联系作者')
time.sleep(100000)
count=1
for url in urls:
url=replace(r'https://8.130.136.54',url,r'https://www.bamboo22.top')
print("开始提取第%d篇网页"%count)
print(url)
fakeblog = s.get(url)
title=find(r'(.*?) - Bamboo22的博客',fakeblog.text)
content=find(r'(.*?)'+"
文末附加内容
",fakeblog.text)
imgs=findall(r"data-fancybox='post-images' href='(.*?)'>

"
content=replace(r"