
- 正则就是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子,在爬虫中,我们需要使用正则在requests得到的响应中提取出网页源码中有用的内容.
- 感觉beautifulsoup库的作用和正则差不多,相当于以函数的形式包装了正则语句吧
正则函数
-
'stri\ng'和r'stri\ng'的区别是后者加了r去除了转义字符,前者相当于"stri换行g",后者是"stri\ng".正则中会使用\,为了防止转义,正则匹配表达式(pattern)都要加r前缀
-
text:需要得到处理的字符串
-
pattern:正则匹配表达式,即后面的匹配模式
-
flags:标志位,结合正则常量用于控制正则表达式的匹配方式
单次匹配
- re.search(pattern,text,flag): 查找任意位置的匹配项,在第一次找到之后就停止匹配,在单次匹配中,匹配结果会返回对象,如果没有匹配到会返回None对象,如果匹配到则可以使用group()函数来获取得到的匹配字符串.
import re
text="miaowumiao"
pattern=r"miao"
result=re.search(pattern,text)
if result==None:
print("匹配失败")
else:
print("search:"+result.group())
import re
text="miaowumiao"
pattern=r"miao1"
result=re.search(pattern,text)
if result==None:
print("匹配失败")
else:
print("search:"+result.group())
- 注意,search没有groups()函数,使用会报错,获取整体匹配结果只能使用group(),如果匹配模式中使用了括号来拆分了匹配部分,那么可以使用group(n)来单独匹配每个部分
- group()或者group(0)表示匹配结果整体,group(n)表示pattern中第n个括号中被匹配到的内容,在后面的匹配模式板块也会提到.
import re
text="miaowumiao"
pattern=r"(mi)(ao)"
#匹配字符串miao,但是mi作为第一部分,ao作为第二部分
#所以group()和group(0)得到miao,group(1)得到mi,group(2)得到ao
result=re.search(pattern,text,re.DOTALL)
if result==None:
print("匹配失败")
else:
print("search:"+result.group(2))
多次匹配
- re.findall(pattern,text,flag): 从字符串任意位置查找,返回一个列表,所有匹配结果都将存于列表中
import re
text="miaowumiao"
pattern=r"miao"
results=re.findall(pattern,text)
if results==None:
print("匹配失败")
else:
i=0
for result in results:
i=i+1
print("第%d次匹配:"%i,result)
正则替换
- re.sub(pattern, repl, text, flag) :repl替换掉text中被pattern匹配的字符,flag表示正则常量。
import re
repl="wang"
text="miaowumiao"
pattern=r"miao"
text=re.sub(pattern,repl,text)#注意转换后要赋值回去
print(text)
- 和正则匹配不同,在正则替换中即使匹配不到也不用做None的检查了
import re
repl="wang"
text="miaowumiao"
pattern=r"miao1"
text=re.sub(pattern,repl,text)
print(text)

正则分割
- re.split(pattern, string,flag)函数:用 pattern 分开 string ,maxsplit表示最多进行分割次数,flag表示后面的正则常量,返回一个数组,匹配结果不包括pattern
import re
text="miaowumiao"
pattern=r"i"
texts=re.split(pattern,text)
print(texts)
正则常量
-
正则常量使用于正则函数的flag的位置,用于完善正则匹配模式(虽然正则表达式也可以实现相同功能,但是正则常量会简单一些),比如在MIAOWUmiao中同时匹配出miao和MIAO,我们可以使用正则常量re.IGNORECASE来忽略大小写进行匹配
-
正则常量在所有正则函数中的使用方法是一样的,下面只使用findall函数来举例
IGNORECASE
- 正则中pattern和text是大小写敏感的,这个常量用于忽略text内容的大小写
- 使用前
import re
text="miaowuMIAO"
pattern=r"miao"
results=re.findall(pattern,text)
if results==None:
print("匹配失败")
else:
i=0
for result in results:
i=i+1
print("第%d次匹配:"%i,result)
(只能匹配到第一个miao)
- 使用后
import re
text="miaowuMIAO"
pattern=r"miao"
results=re.findall(pattern,text,re.IGNORECASE)
if results==None:
print("匹配失败")
else:
i=0
for result in results:
i=i+1
print("第%d次匹配:"%i,result)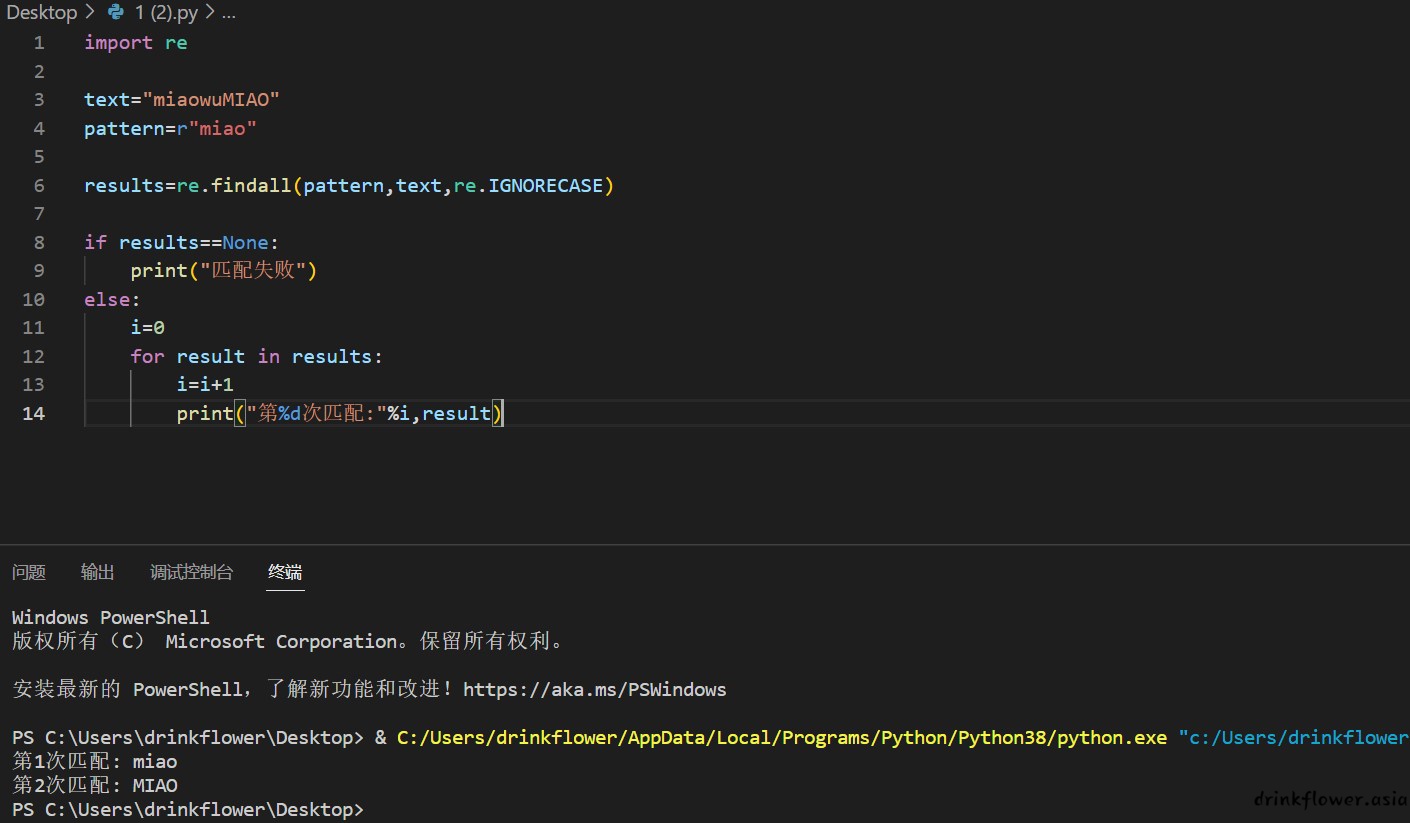
(大小写都匹配成功)
ASCII
- re.ASCII常量让 \w, \W, \b, \B, \d, \D, \s 和\S只匹配ASCII,而不是整个字符串(比如汉字),后面会提到这些匹配的意思
- 比如r"\w+"是匹配连续的长字符串,那么r"\w+"匹配"miaowumiao666"啊就会得到"miaowumiao"啊,使用re.ASCII仅能匹配到"miaowumiao"
import re
text="miaowumiao啊"
pattern=r"\w+"
results=re.findall(pattern,text)
if results==None:
print("匹配失败")
else:
i=0
for result in results:
i=i+1
print("第%d次匹配:"%i,result)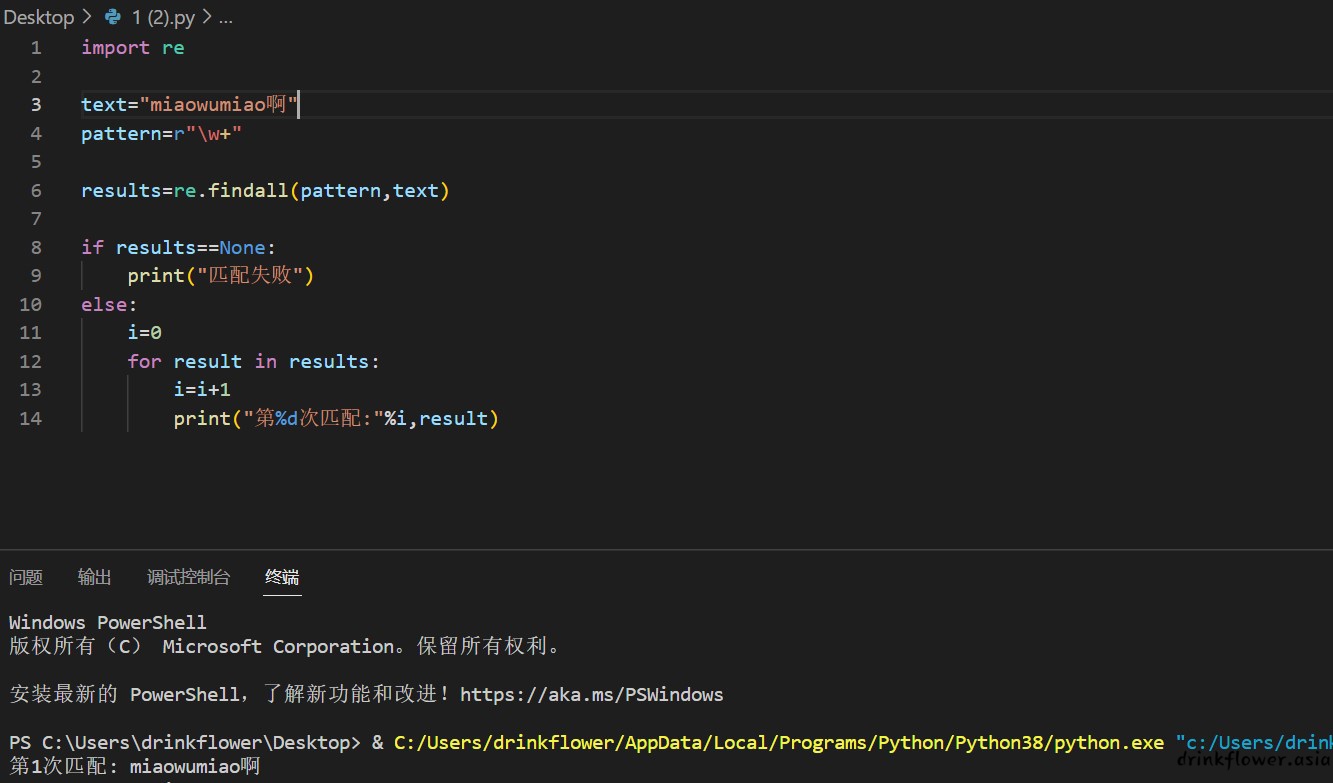
(能匹配到unicode)
import re
text="miaowumiao啊"
pattern=r"\w+"
results=re.findall(pattern,text,re.ASCII)
if results==None:
print("匹配失败")
else:
i=0
for result in results:
i=i+1
print("第%d次匹配:"%i,result)
(中文不是ascii,匹配不到)
DOTALL
- 正则匹配默认不能匹配一些特殊符号,比如换行符\n我们可以使用正则常量DOTALL来各种特殊符号(实际测试下,我的环境默认是允许多行匹配和匹配所有的🤣)
import re
text="miao\nwu\nmiao"
pattern=r"\n"
results=re.findall(pattern,text,re.DOTALL)
if results==None:
print("匹配失败")
else:
i=0
for result in results:
i=i+1
print("第%d次匹配:"%i,result)
MULTILINE
- 正则匹配在使用^模式匹配(匹配文本开头)时是不能匹配多行文本的,当text有多行且我们需要匹配开头时,我们可以使用正则常量MULTILINE来匹配多行
import re
text="miao\nwu\nmiao"
pattern=r"^miao"
results=re.findall(pattern,text)
if results==None:
print("匹配失败")
else:
i=0
for result in results:
i=i+1
print("第%d次匹配:"%i,result)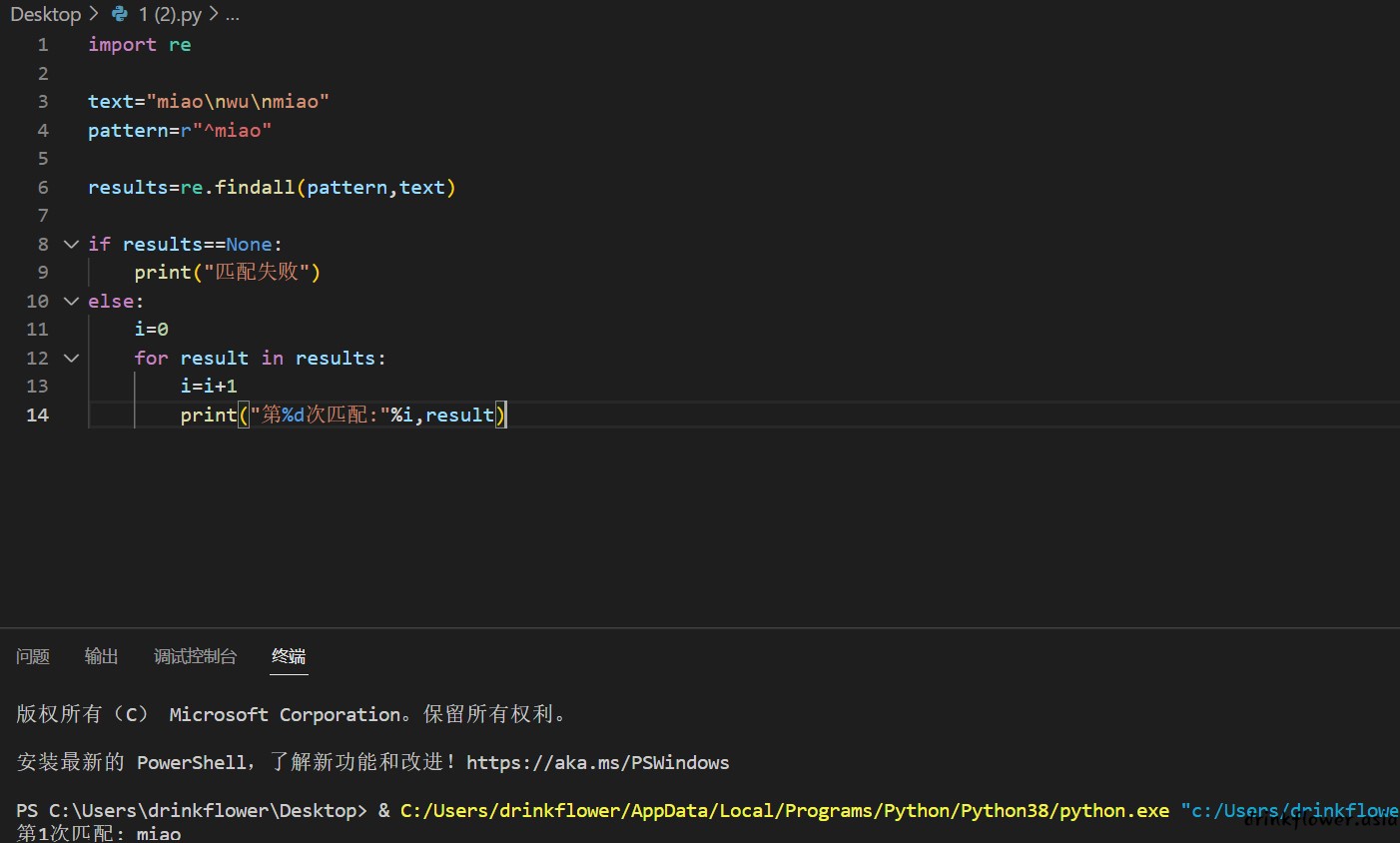
(只匹配到第一行的)
import re
text="miao\nwu\nmiao"
pattern=r"miao"
results=re.findall(pattern,text,re.MULTILINE)
if results==None:
print("匹配失败")
else:
i=0
for result in results:
i=i+1
print("第%d次匹配:"%i,result)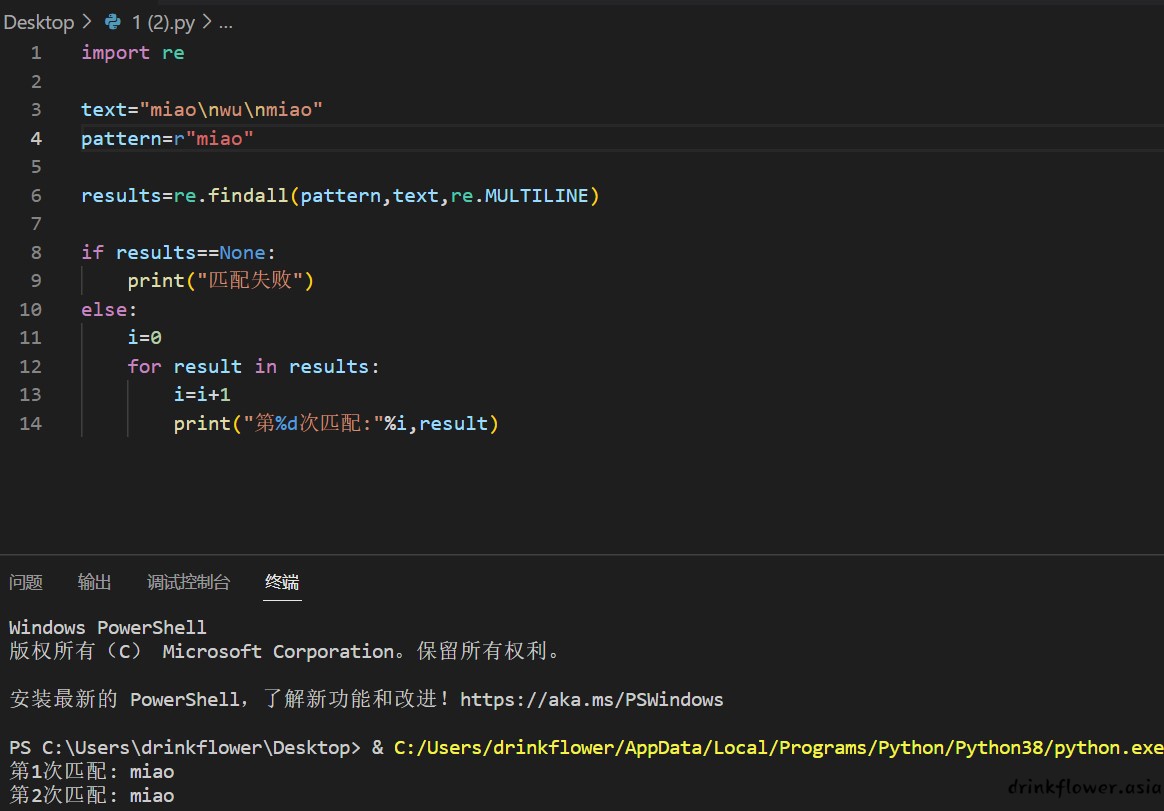
(两行都匹配到了)
匹配模式
基础概念
- 为了满足能够在任何复杂情况下,正则表达式都能随心所欲的匹配到任意想要的内容,整个匹配模式的知识点复杂繁多,这里只列举一些常用的模板,并在结尾贴出所有模式语法中的特殊元素.
- 注意,针对某种特殊句子的正则表达式通常不是唯一的,比如想要匹配出一段文本中的全部ip地址(数字.数字.数字.数字)以下两种匹配模式都是可以的,显然后者会简单很多
(?<![\.\d])(([1-9]?\d|1\d\d|2[0-4]\d|25[0-5])\.){3}([1-9]?\d|1\d\d|2[0-4]\d|25[0-5])(?![\.\d])\d+.\d+.\d+.\d+- 当想要验证正则表达式语法是否正确,或者能否成功匹配到目标,可以使用这个网站https://regex101.com/
- 将正则表达式放在regular expression里面,将代匹配的文本放在test string里面,匹配信息会出现在右边栏的match information里面

- 同时,如果正则表达式中使用了括号分组,匹配到的每组的信息也会以group(n)的形式呈现

常用语法
-
单个字符即表示单个字符本身(特殊字符除外),比如可以用miao匹配miao
-
字符类,可以单独使用,代替了一类字符
. 匹配除 "\n" 之外的任何单个字符。
\d 匹配一个数字字符。
\D 匹配一个非数字字符。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。
\S 匹配任何非空白字符。
\w 匹配包括下划线的任何字符(数字也匹配)。
\W 匹配任何非单词字符(数字也不匹配)。- 模式类,不能单独使用,要配合字符类使用
^ 匹配字符串的开头
$ 匹配字符串的末尾。
* 重复*前面表达式0次或多次。
re+ 重复+前面表达式1次或多次。
re? 重复?前面表达式0次或1次。
(re) 对正则表达式分组并记住匹配的文本- 正则表达式多个部分之间连接不需要任何符号,比如从曜的连招"33a213a"中匹配出以数字字母开头,字符结尾的两位字符的匹配只需要\D\d,得到"a2"

- 如果匹配成功后需要单独取出a和2才需要加括号变为(\D)(\d)

常用模板-固定格式
- 如果是匹配固定格式内容,可以使用上面常用语法提到的常用字符类+常用模式类+正则常量的组合,比如\d表示数字,+表示重复一次或多次,所以\d+表示多个数字,\S+表示字符串.
- 举个例子,从以下文本中匹配出所有的形如"miao:127.0.0.1"的字符串的正则表达式可以写成
\S+:\d+.\d+.\d+.\d+ Automatically created by: scrapy startproject
登录用户miao:192.168.1.2
For more information about the [deploy] section see:
登录用户wang:127.0.0.1
https://scrapyd.readthedocs.io/en/latest/deploy.html
- 但是这种情况下,会把不想要的登录用户字符也带进去,那么直接用前面提到的re.ASCII正则常量,即可实现忽略掉中文
常用模板-固定开头结尾
- 有时,要匹配的内容不是固定的,但是它们有固定的开头结尾,就可以使用"开头标志(.)结尾标志"来匹配内容,开头标志和原文标志一致,结尾标志和原文一致,中间匹配到的内容用(.*)匹配,.表示单个任意字符,*表示重复0次或多次,(.\)就表示了开头结尾之间可能存在的所有内容
- 举个例子,从以下文本中匹配出所有:之后的内容的正则表达式可以写成
r":(.*)\n"这个错误提示 'gbk' codec can't decode byte 0xa6 in position 4: illegal multibyte sequence 表示在使用 'gbk' 编码解码时,遇到了非法的多字节序列。情感分析结果是:负向 把握99.213300% 负向程度99.646000%
情感分析结果是:中性
这个错误通常发生在尝试使用错误的编码方式解码字符串时。可能是因为字符串的实际编码与你指定的 'gbk' 编码方式不匹配导致的。情感分析结果是:负向 把握99.792700% 负向程度99.906700%
情感分析结果是:中性
要解决这个问题,可以尝试以下几种方法:情感分析结果是:负向 把握44.274400% 负向程度74.923500%
情感分析结果是:中性
确认使用正确的编码方式:请检查字符串的实际编码方式,确保与你指定的 'gbk' 编码方式相匹配。情感分析结果是:负向 把握53.611100% 负向程度79.125000%
情感分析结果是:中性
使用正确的编码方式进行解码:如果你确认字符串采用了其他编码方式,可以尝试使用正确的编码方式进行解码,例如 'utf-8'。情感分析结果是:中性
情感分析结果是:中性
python情感分析结果是:正向 把握92.343800% 正向程度96.554700%
string = b'\xa6'情感分析结果是:正向 把握78.493500% 正向程度90.322100%
decoded_string = string.decode('utf-8')情感分析结果是:正向 把握63.117700% 正向程度83.403000%
print(decoded_string)情感分析结果是:正向 把握73.309300% 正向程度87.989200%
输出结果会根据实际的编码方式而有所不同,这里使用 'utf-8' 编码仅作为示例。情感分析结果是:正向 把握59.112600% 正向程度81.600700%
情感分析结果是:中性
忽略错误的字节:如果不确定字符串的编码方式或无法更改编码方式,可以尝试在解码过程中忽略错误的字节。情感分析结果是:负向 把握95.517700% 负向程度97.983000%
情感分析结果是:中性
python情感分析结果是:正向 把握92.343800% 正向程度96.554700%
string = b'\xa6'情感分析结果是:正向 把握78.493500% 正向程度90.322100%
decoded_string = string.decode('gbk', errors='ignore')情感分析结果是:正向 把握38.152600% 正向程度72.168700%
print(decoded_string)情感分析结果是:正向 把握73.309300% 正向程度87.989200%
这样做会忽略无法解码的字节,但也可能导致输出结果不完整或含有乱码。情感分析结果是:负向 把握99.634300% 负向程度99.835400%
情感分析结果是:中性
请根据具体情况选择适合的方法来解决该错误。如果问题仍然存在,请提供更多的上下文信息,以便更好地帮助你解决问题。情感分析结果是:负向 把握67.160000% 负向程度85.222000%import re
text=open("666.txt").read()
pattern=r":(.*)\n"
results=re.findall(pattern,text)
if results==None:
print("匹配失败")
else:
i=0
for result in results:
i=i+1
print("第%d次匹配:"%i,result)
- 本来到这里就结束了,但是在jwt脚本的编写时出了一点问题,导致贪婪匹配的问题暴露了出来
- ==比如使用r"a(.*)b"在匹配以下内容时就会两种情况,匹配到以a开头,b结尾的"a66b",或者匹配到以a开头,b结尾的"a66b66b",因为(.*)是贪婪匹配,所以匹配到的是后者.==
- 在这个模板的常见使用情况下,一般都是要匹配最短的,就得去除贪婪模式,所以应该使用==r"a(.*?)b"==
表达式大全
- 这两种模板已经可以解决很多情况下的匹配了,在面对某些难以解决的情况还得加其他的表达式,这里贴一份
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 精确匹配 n 个前面表达式。例如, o{2} 不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的两个 o。 |
| re{ n,} | 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。"o{1,}" 等价于 "o+"。"o{0,}" 则等价于 "o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | 对正则表达式分组并记住匹配的文本 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符,等价于 [ \t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
| 字符 | 描述 |
|---|---|
| python | 匹配 "python". |
| 字符类 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
| 特殊字符类 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |