
- 最近期末考试,堆了好多报告,慢慢补吧
发送请求
- 爬虫需要实现发送网络请求,通常使用urllib库或者requests库,但是python3导入urllib库太麻烦了,就以requests为例(emmmm~requests好像原本也是urllib库里的).
pip install requests- http都常用请求方式requests库都有相应的函数,如:
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')处理返回值
- requests对象的get和post方法都会返回一个Response对象,这个对象里面存的是服务器返回的所有信息,包括响应头,响应状态码等。其中返回的网页部分会存在.content和.text两个属性中。
- content是二进制信息,text是content被ascll编码后的信息.如果页面只有文本(这并不意味着没有图片而是比如没有图片源数据,图片仅通过标签插入到网页)那么用text即可,如果有图片视频等文件的源数据,只能使用content来显示文件的内容
- 正常情况直接用text即可
import requests
response = requests.get("https://www.baidu.com")
print(response.text)
- 有二进制数据时使用content
import requests
response = requests.get("https://drinkflower.asia/wordpress/wp-content/uploads/3.png")
print(response.text)
print("上面是tetx,下面是content")
print(response.content)
(可以看到当请求对象是图片时,text能正常返回而content不行)
- 这种情况下,content获取了二进制数据只是打印出来是没有什么用的,可以配合写文件来将数据保存到本地
import requests
r = requests.get('https://drinkflower.asia/wordpress/wp-content/uploads/3.png')
with open('3.png', 'wb') as f:
f.write(r.content)
- 当请求对象含有中文文本时,使用content然后.decode('utf-8')手动编码,因为text对中文的自动编码可能会出错
import requests
response = requests.get("https://www.baidu.com")
print(response.content.decode('utf-8'))
(可以看到text的返回值有一些乱码,而utf-8编码后的content显示全部正常)
传递参数
-
下面所使用的https://httpbin.org/get,https://httpbin.org/post等链接的网站如果检测到对应的访问,会返回访问时的http报文,可以帮助访问者了解自己的请求)
-
处理完返回值,重新回到请求,有的时候我们的get,post方法需要传一些参数进去
-
上面提到,直接get可以发送一个简单的get请求,那么当需要get传参的时候可以将参数写到请求里面
-
使用params参数来传递参数
import requests
response = requests.get("https://httpbin.org/get")
print(response.text)
print("上面无参数,下面有参数")
response1 = requests.get("https://httpbin.org/get?id=drinkflower")
print(response1.text)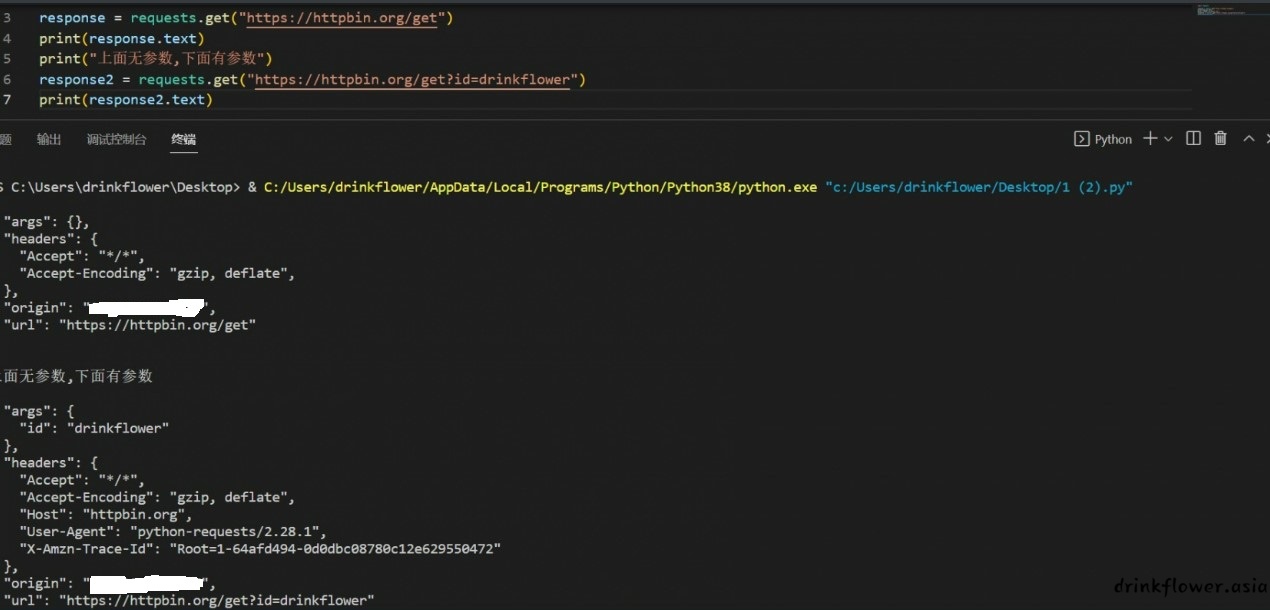
(arg项有了id一值)
- get传参可以这样,但是post传参显然就不能这么用了,所以还是统一用params参数来传参比较好,get方法如下:
import requests
param={
'user': 'drinkflower',
'pwd': 114514
}
response = requests.get("https://httpbin.org/get",params=param)
print(response.text)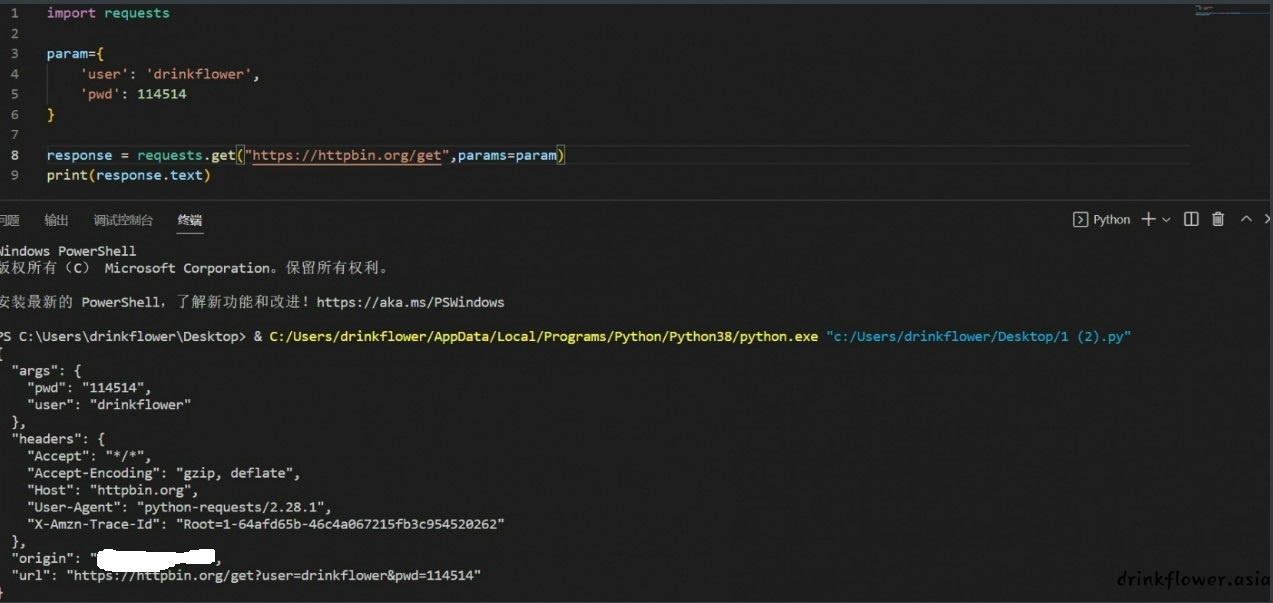
(arg项有了传入值)
- post传参也是一样的
import requests
param={
'user': 'drinkflower',
'pwd': 114514
}
response = requests.post("https://httpbin.org/post",params=param)
print(response.text)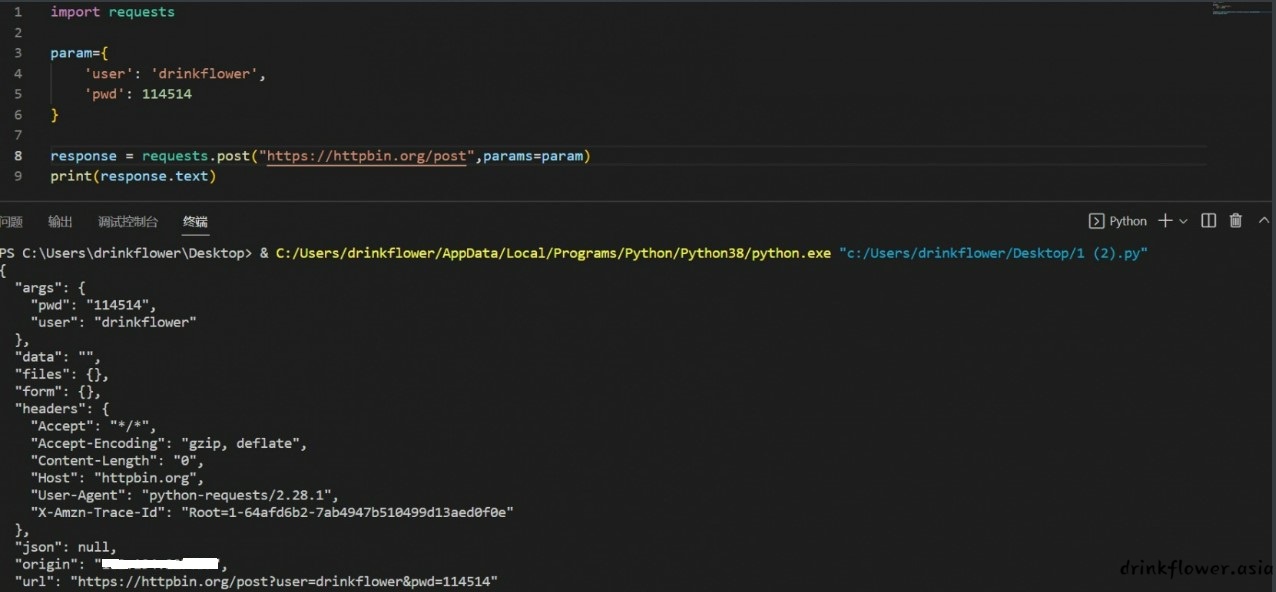
(arg项有了传入值)
伪造请求头
- 很多时候网站会做一些简单的反爬虫措施来阻止爬虫,比如检查UA是否为python,或者利用referer实现图片防盗链,我们可以利用requests的header参数将请求伪造成普通用户的请求.这里只举例常用的get和post(如果需要也可以伪造其他的首部字段)
- 使用headers参数来伪造请求头
import requests
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
'referer': 'https://drinkflower.asia'
}
response = requests.get("https://httpbin.org/get",headers=header)
print(response.text)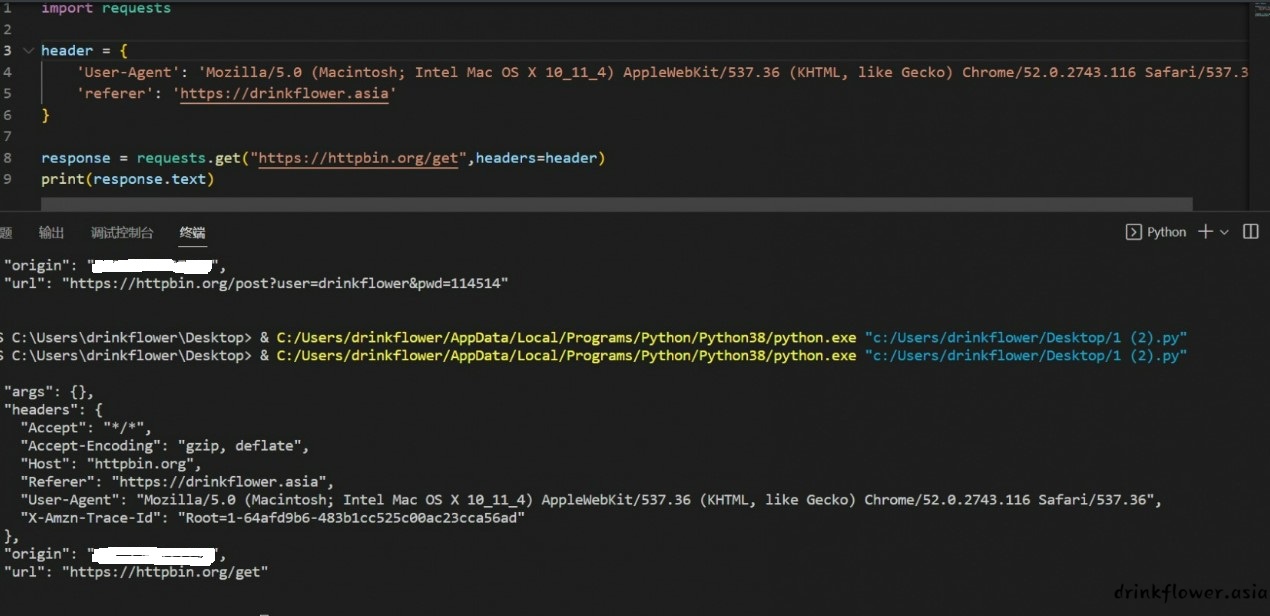
(成功伪造了ua和referer)
- post也是一样
import requests
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
'referer': 'https://drinkflower.asia'
}
response = requests.post("https://httpbin.org/post",headers=header)
print(response.text)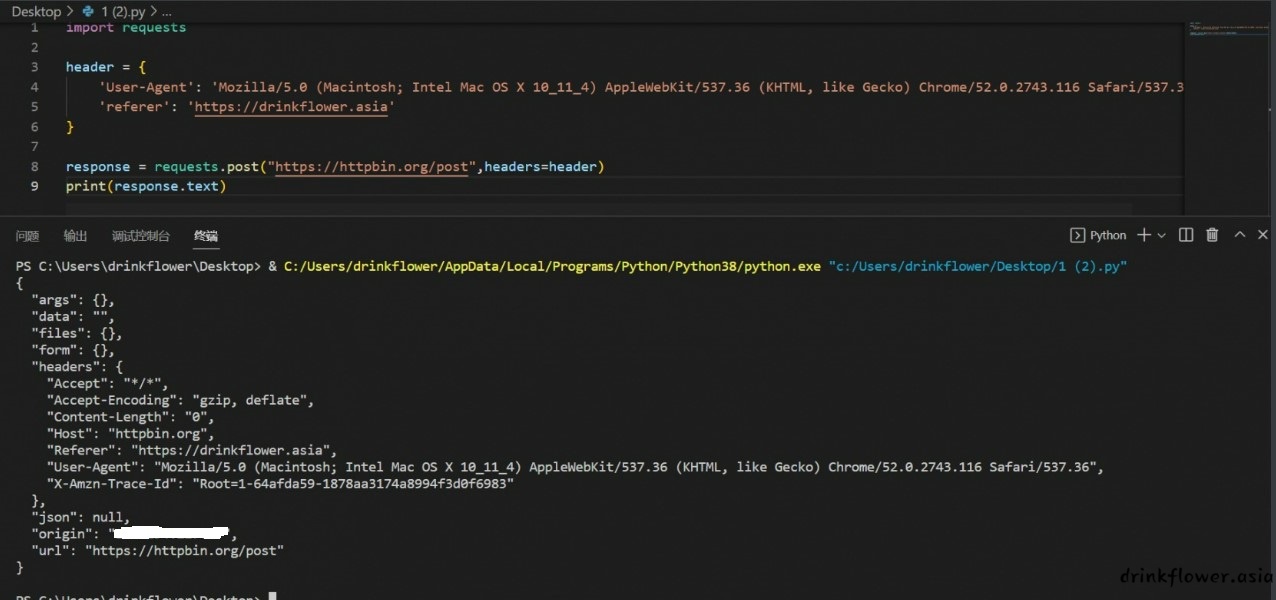
伪造cookie
- 当网站需要登录,可以利用cookie来伪造登录状态
- 使用headers参数来伪造cookie,cookie比较重要,所以单独拎出来
import requests
header = {
'cookie': 'miao=wang;wang=miao'
}
response = requests.get("https://httpbin.org/get",headers=header)
print(response.text)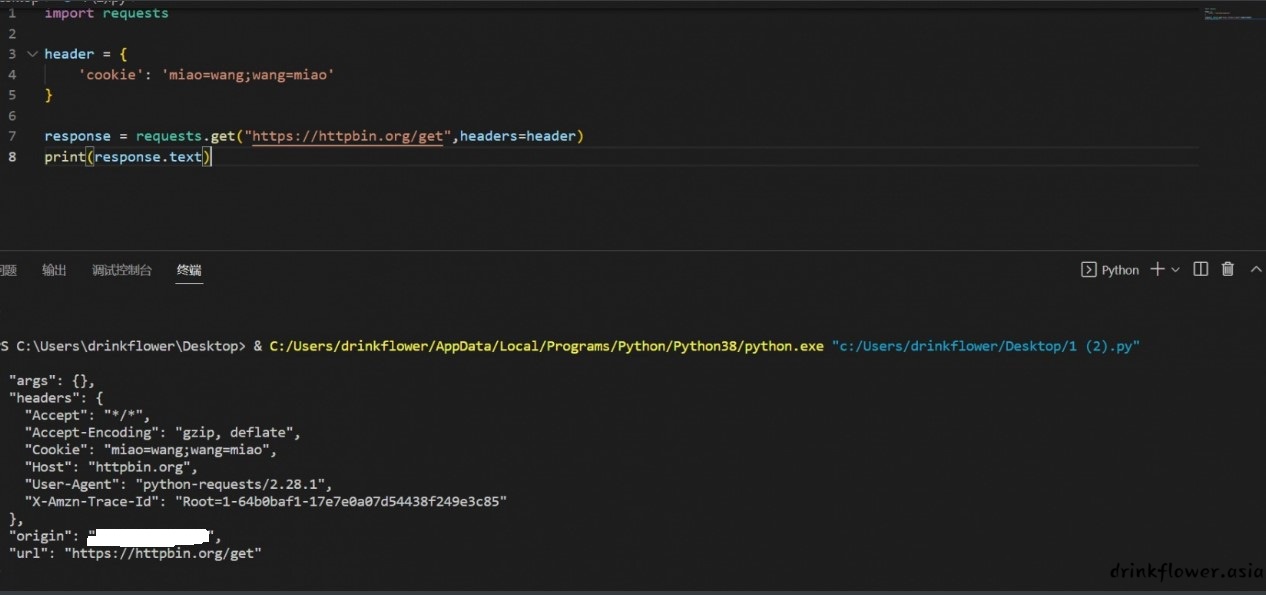
- post也是一样的
import requests
header = {
'cookie': 'miao=wang;wang=miao'
}
response = requests.post("https://httpbin.org/post",headers=header)
print(response.text)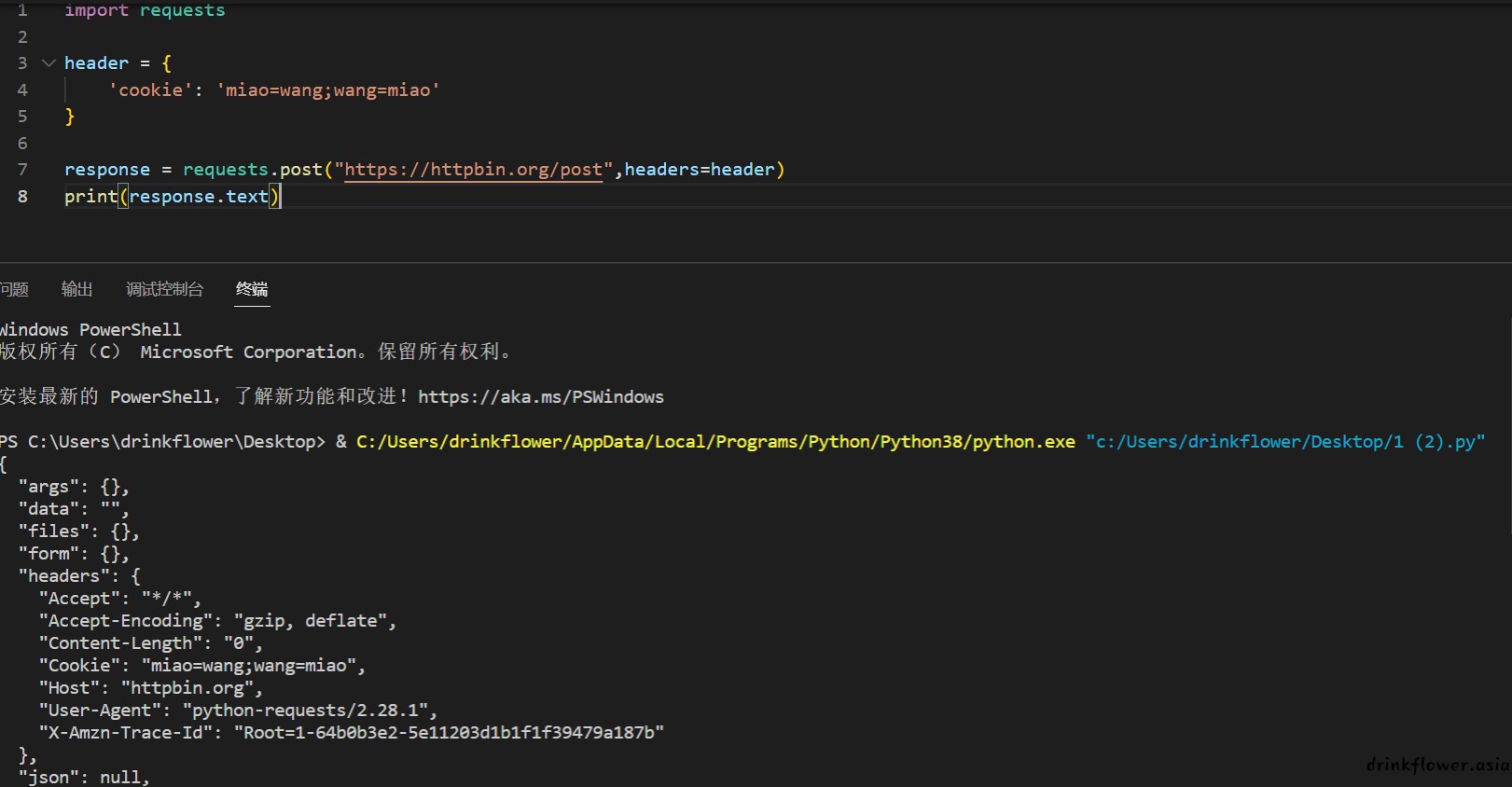
- 也可以使用cookies参数
import requests
cookie = {
'miao':'wang',
'wang':'miao'
}
response = requests.get("https://httpbin.org/get",cookies=cookie)
print(response.text)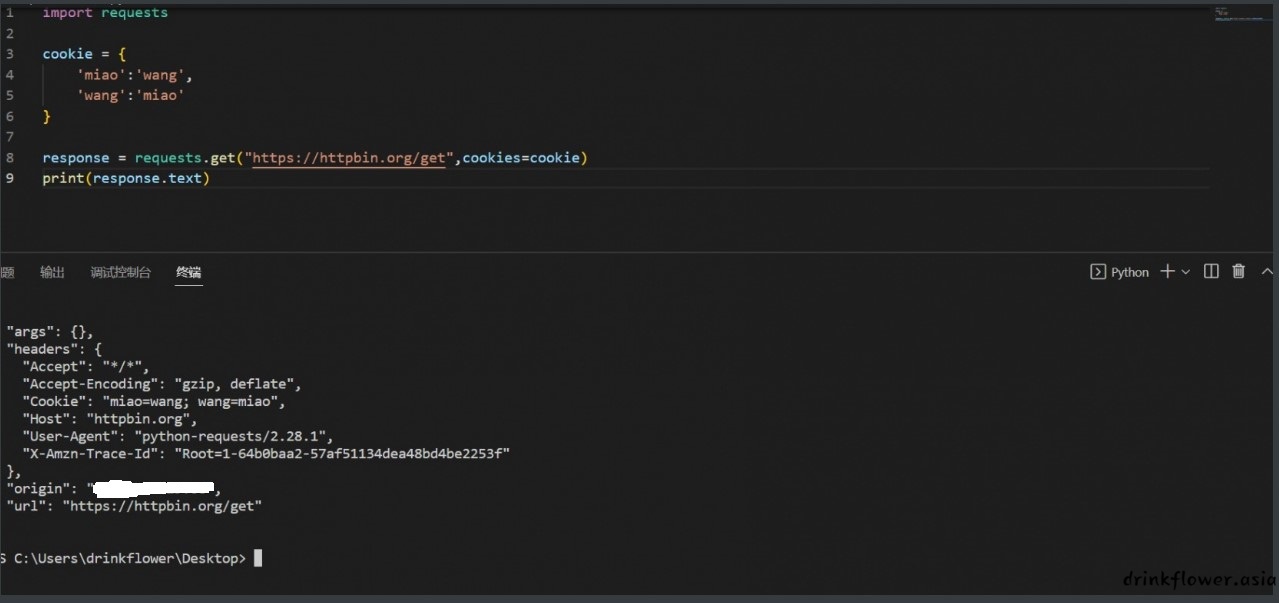
- post也是一样
import requests
cookie = {
'miao':'wang',
'wang':'miao'
}
response = requests.post("https://httpbin.org/post",cookies=cookie)
print(response.text)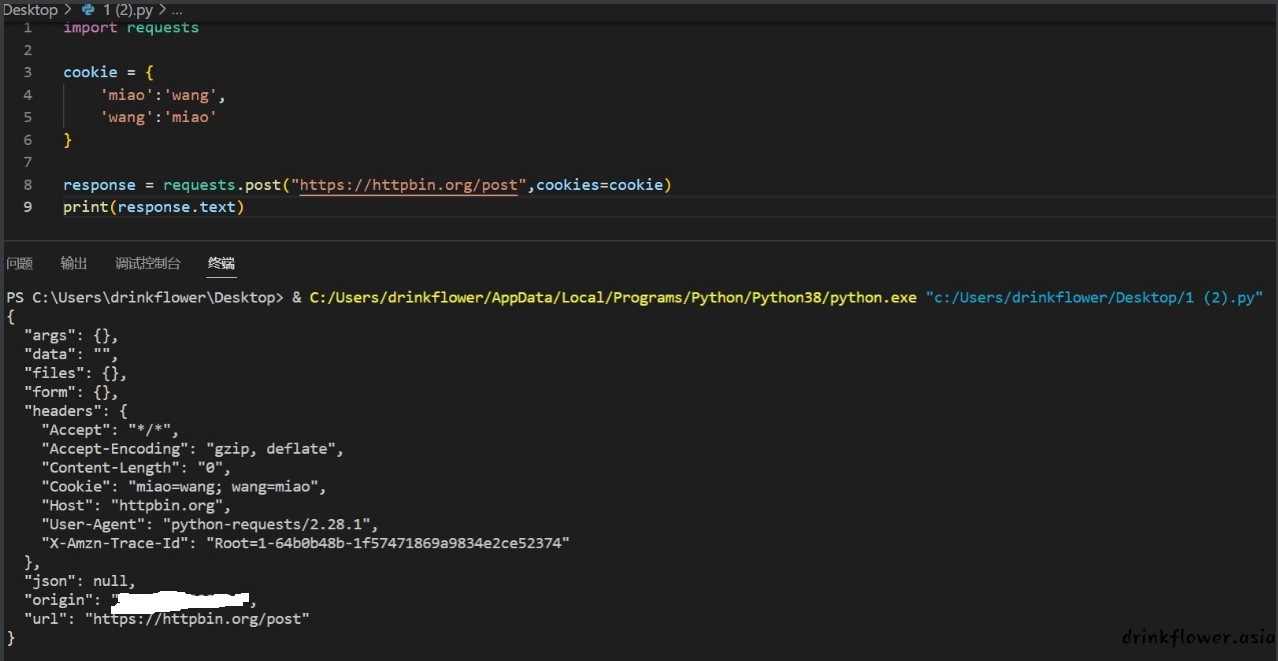
添加代理
- 爬虫可能不会运行在本机上,所以的运行环境不一定易于访问部分网站,可以添加代理
- 使用proxies参数来添加代理,如果代理有用户名密码,可以使用http(s)://用户名:密码@ip:端口的形式实现验证,但是我在本地测试是没有成功的,感觉因为用户名或者密码中有特殊符号却无法转义
import requests
proxy = {
'http': 'http://10.10.10.10:1080',
'https': 'http://10.10.10.10:1080'
}
response = requests.get("https://httpbin.org/get",proxies=proxy)
print(response.text)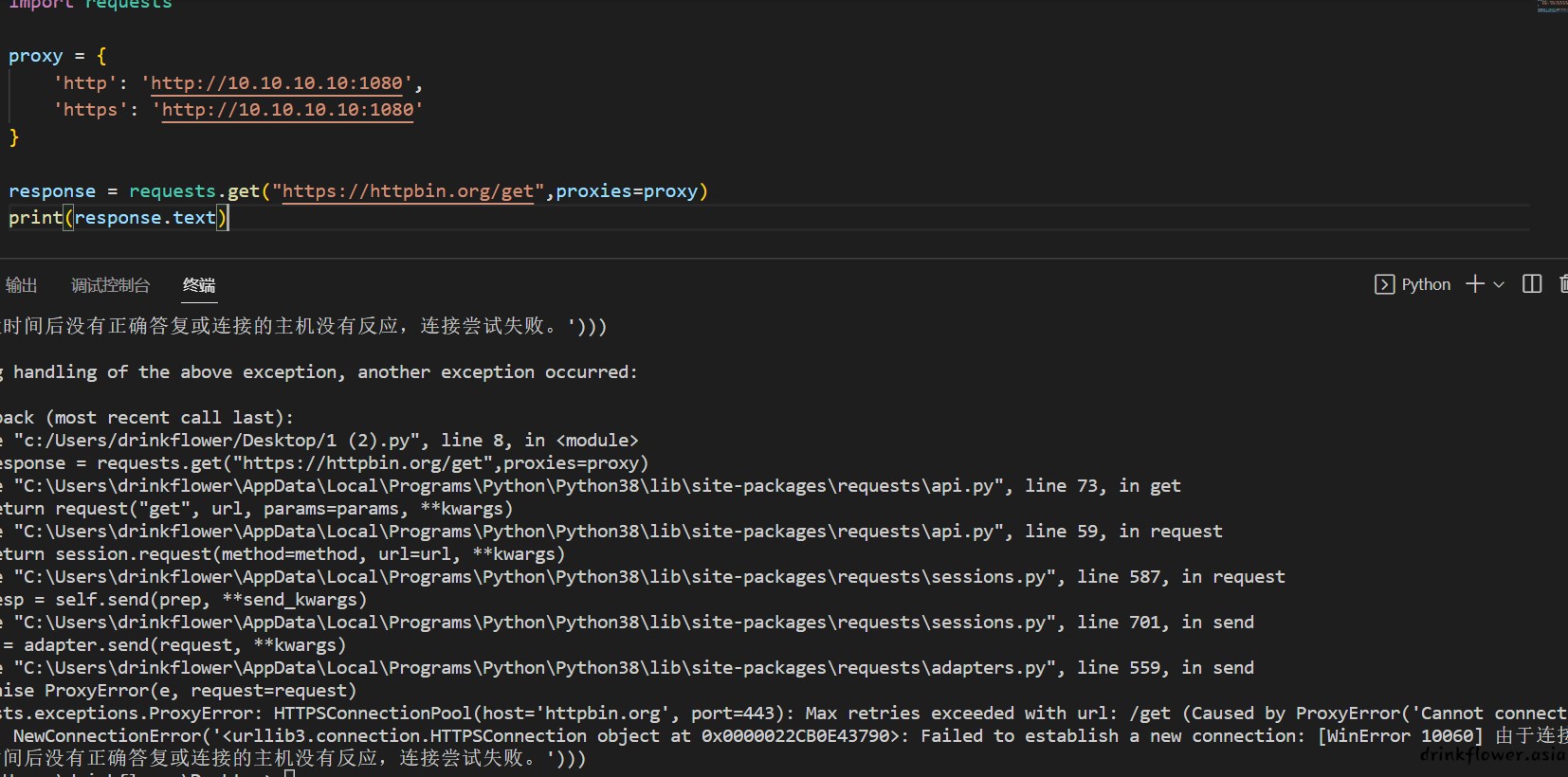
- post也是一样
import requests
proxy = {
'http': 'http://10.10.10.10:1080',
'https': 'http://10.10.10.10:1080'
}
response = requests.post("https://httpbin.org/post",proxies=proxy)
print(response.text)超时控制
- 单个请求耗时过长可能导致总体任务出现问题,可以为单个请求添加时长限制
- 使用timeout参数控制超时时间,如果超时,程序会抛出错误退出,需要配合后面的处理响应
import requests
proxy = {
'http': 'http://10.10.10.10:1080',
'https': 'http://10.10.10.10:1080',
}
response = requests.get("https://httpbin.org/get",proxies=proxy,timeout = 2)
print(response.text)
- post也是一样
import requests
proxy = {
'http': 'http://10.10.10.10:1080',
'https': 'http://10.10.10.10:1080',
}
response = requests.post("https://httpbin.org/post",proxies=proxy,timeout = 2)
print(response.text)
忽略证书错误
- 有些网站可能并没有设置好 HTTPS 证书,或者网站的 HTTPS 证书可能并不被 CA 机构认可,这时候,这些网站可能就会出现 SSL 证书错误的提示。比如edge打开https://ssr2.scrape.center/会显示

- 通常在高级选项下有继续访问的提示

- 但是如果用爬虫处理这个网站就会出现异常
import requests
response = requests.get("https://ssr2.scrape.center/")
print(response.text)
- 网站本身是可以访问的,只需要爬虫忽略证书错误,使用verify参数,本地测试提示urllib3库又没有,这个库超级难用
#urllib日常用不了
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get("https://ssr2.scrape.center/")
print(response.text)- 可以使用logging库实现相同功能
import requests
import logging
logging.captureWarnings(True)
response = requests.get("https://ssr2.scrape.center/",verify=False)
print(response.text)
- post也是一样
import requests
import logging
logging.captureWarnings(True)
response = requests.post("https://ssr2.scrape.center/",verify=False)
print(response.text)
会话维持
- 在 requests 中,如果直接利用 get 或 post 等方法的确可以做到模拟网页的请求,但是这实际上是相当于不同的 Session.也就是说即使用爬虫访问了两次相同网页,也相当于你用了两个浏览器打开了相同的页面,先前的网页状态全部没了.
- 我们有测试网址 https://httpbin.org/cookies/set/number/123456789。请求这个网址时,可以设置一个 Cookie 条目,名称叫作 number,内容是 123456789,随后又请求了 https://httpbin.org/cookies,此网址可以获取当前的 Cookie 信息。不做会话维持时,设置的cookie在第二次访问时已经失效了.
import requests
requests.get('https://httpbin.org/cookies/set/number/123456789')
r = requests.get('https://httpbin.org/cookies')
print(r.text)
- 使用session函数来实现会话维持,第一次设置的cookie仍然有效
import requests
s = requests.Session()
q=s.get('https://httpbin.org/cookies/set/number/123456789')
print(q.text)
r = s.get('https://httpbin.org/cookies')
print(r.text)
处理响应
- 使用status_code属性来处理网页响应和捕获错误
import requests
proxy = {
'http': 'http://10.10.10.10:1080',
'https': 'http://10.10.10.10:1080',
}
response = requests.get("https://httpbin.org/get")
print(response.status_code)