
验证脚本
- 将下面正则知识的部分写完已经感觉头昏脑胀了,但是所学的知识还只是正则中的一小部分,试着随便拿了一道题目来练了一下手,结果还是不能完全看懂正则表达式,比如下面这个例子:
正则
/[oc]:\d+:/i字符串
O:11:"ctfShowUser":4:{s:21:"ctfShowUserusername";s:6:"xxxxxx";s:21:"ctfShowUserpassword";s:6:"xxxxxx";s:18:"ctfShowUseris
Vip";b:0;s:18:"ctfShowUserclass";O:8:"backDoor":1:{s:14:"backDoorcode";s:23:"system('ca
t flag.php');";}} - 上面的例子中过滤了O:11:字符串,用眼睛看是比较难受的,但是幸运的是可以利用脚本来测试哪些字符串会受到过滤
- preg_match函数提供了受到匹配的字符串部分,就可以写个小脚本来测试指定字符串的哪些部分被正则匹配了
- 只需要把正则表达式和匹配字符串填入两个参数即可
<?php
$patten="/[oc]:\d+:/i";
$in='O:11:O:8:"backDoor":1:{s:14:"backDoorcode";s:23:"system("cat flag.php");";}} ';
$a = preg_match_all($patten,$in,$mc);
var_dump($mc);
?>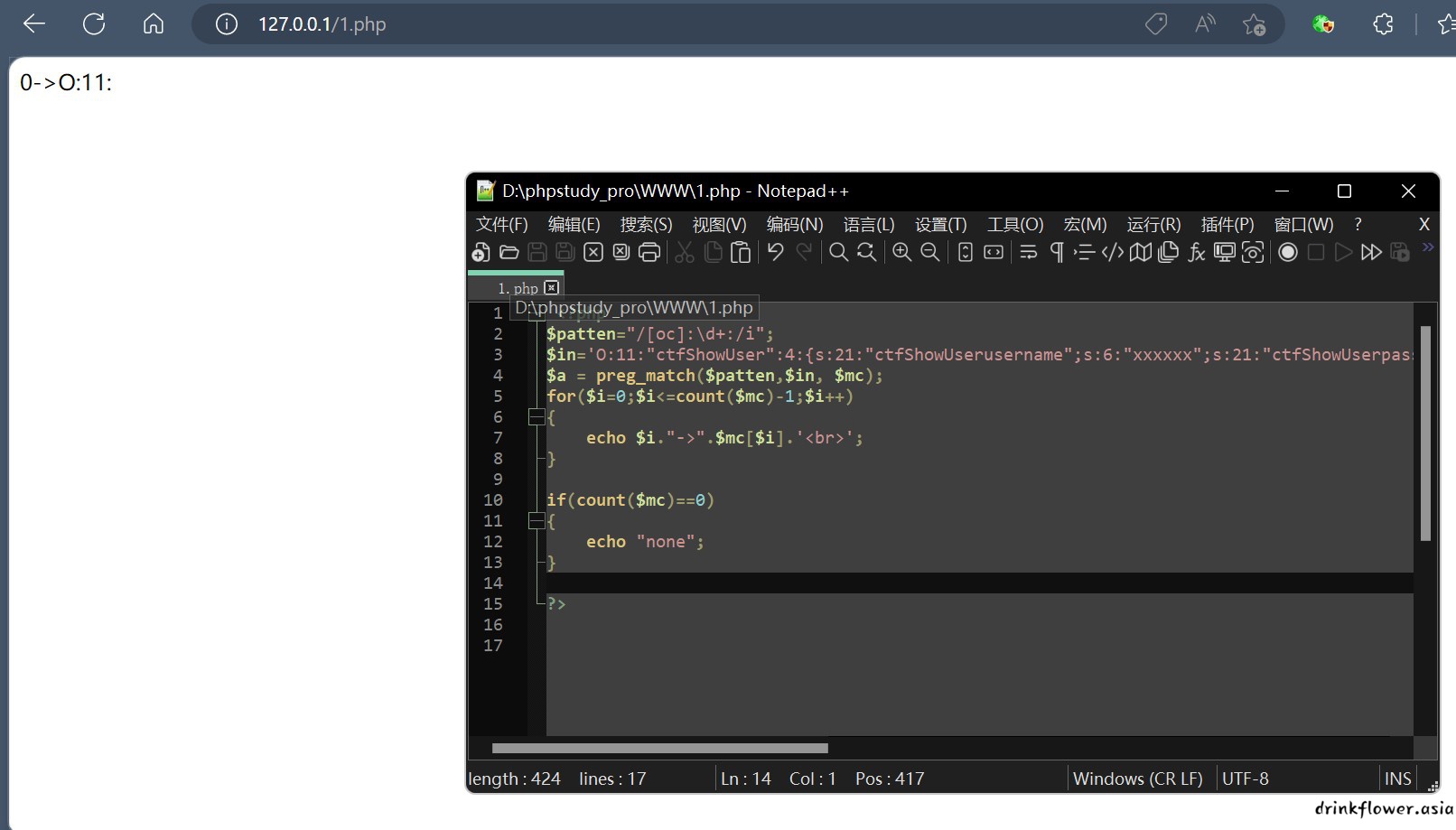
(出了问题,改了一下)
- 由于存在模糊匹配,试图列举出一个正则的所有匹配字符串是不可能的,只能做到这一步了
显式字符
[ABC]
- 匹配 [...] 中的所有字符,例如 [aeiou] 匹配字符串 "google runoob taobao" 中所有的 e o u a 字母。
[^ABC]
- 匹配除了 [...] 中字符的所有字符,例如 [^aeiou] 匹配字符串 "google runoob taobao" 中除了 e o u a 字母的所有字母。
[A-Z]
- [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。
.
- 匹配除换行符(\n、\r)之外的任何单个字符,相等于[^\n\r]。
[\s\S]
- 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。
\w
- 匹配字母、数字、下划线。等价于 [A-Za-z0-9_]
特殊字符
- 所有特殊字符防止转义都是加\
\
- 用来匹配单字符,例如/a7M/可以匹配a7M
*
- 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。
+
- 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。
?
- 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 "do" 、 "does"、 "doxy" 中的 "do" 和 "does"。
{n}
- n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 "Bob" 中的 o,但是能匹配 "food" 中的两个 o。
{n.m}
- m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 "fooooood"中的前三个 o。
定位符
$
- 匹配字符串结尾
^
- 匹配字符串开头
下面的正则表达式匹配一个章节标题,该标题只包含两个尾随数字,并且出现在行首:
/^Chapter [1-9][0-9]{0,1}/修饰符
- /pattern/flags
i
- ignore - 不区分大小写 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。
var str="Google runoob taobao RUNoob";
var n1=str.match(/runoob/g); // 区分大小写
var n2=str.match(/runoob/gi); // 不区分大小写g
- global - 全局匹配 查找所有的匹配项。
var str="Google runoob taobao runoob";
var n1=str.match(/runoob/); // 查找第一次匹配项
var n2=str.match(/runoob/g); // 查找所有匹配项m
- m 修饰符可以使 ^ 和 $ 匹配一段文本中每行的开始和结束位置。
var str="runoobgoogle\ntaobao\nrunoobweibo";
var n1=str.match(/^runoob/g); // 匹配一个
var n2=str.match(/^runoob/gm); // 多行匹配s
- 默认情况下的圆点 . 是 匹配除换行符 \n 之外的任何字符,加上 s 之后, . 中包含换行符 \n。
var str="google\nrunoob\ntaobao";
var n1=str.match(/google./); // 没有使用 s,无法匹配\n
var n2=str.match(/runoob./s); // 使用 s,匹配\n